「自分の Mac で AI を動かしたい。でも、必要なメモリもモデルの選び方も分からない」——ローカル LLM は入口の用語が多く、最初の一歩で迷いやすい分野です。私も Mac で Ollama を触り、クラウド API と比べるまで、何を基準に選べばよいか整理できませんでした。
結論から言うと、まず軽いモデルを1つ動かし、用途が見えてからメモリやモデルを広げるのが筋です。本記事では必要スペック、主要モデル、日本語対応、5分の最小手順に加え、環境を作ったあと「何を作るか」まで一続きで整理します。
とりあえず最短で「自分の PC で LLM を動かす感触を掴みたい」方は、結論と 5 分で動かす最小手順から読み始めると、本日中に最初の一歩が踏めます。
結論とローカルLLMの全体像|個人検証ではアリ・業務本番はクラウドAPI・クラウドとの4つの違い

📖 この章で使う用語
- LLM(Large Language Model:大規模言語モデル):ChatGPT や Claude などの中身を動かす、文章を予測する装置。詳しくは LLM とは で扱っています。
- ローカル LLM:自分の PC や手元のサーバで動かす LLM の総称。「クラウド AI = レンタル車に対し、ローカル LLM = 自家用車」のイメージ。
- クラウド AI:ChatGPT / Claude / Gemini のように、運営会社のサーバで動く AI。インターネット越しに使う。
- 個人検証レベル:業務本番運用ではなく、自分の PC で触って動かしてみた範囲、という意味。
ローカル LLM は 「個人検証ではアリ、業務本番のメインはクラウド API が筋」——これが、Apple Silicon Mac で Ollama を触り、業務では Anthropic / OpenAI / Google の API を毎日叩いている私の、いちばん実用的な答えです。3 行で覚えるなら、次の住み分けです。
- ローカル LLM = プライバシー・無料・オフライン・カスタマイズ・学習目的(自分の手元で完結する自家用車)
- クラウド AI(API) = 性能・速度・運用負担の軽さ(フル装備で借りるレンタル車)
- 使い分け = 用途と機密性・コスト要件で、ローカルとクラウドを「組み合わせて」運用するのが現実解
新しいツールやモデルが出てきても、「これは自家用車側か、レンタル車側か、組み合わせ用か」を確かめれば置き場所に迷いません。
経験範囲を先に明示します。Code Llama / DeepSeek Coder / Llama 3 を Ollama で動かしたのは個人検証の範囲で、業務本番では使い込んでいません。業務で毎日叩くのは Anthropic / OpenAI / Google の API と、必要に応じて AWS Bedrock 経由 Claude です。Mistral / Gemma / Qwen / Phi・日本語特化モデル(ELYZA-JP / Swallow)は長時間動かし込んでいないため、公式情報や評判をもとに紹介します。小説生成については、自分の企画の第1話を実際に生成する検証を行い、その範囲は本文で明示します。
本記事は LLM とは(LLM 概念ハブ、クラウド主軸)のスポークとして「LLM を自分の PC で動かす」軸に絞り、モデル選びとハードウェア要件を主軸にします。ローカル LLM でのコードレビューは AI コードレビュー のセクション 7、エージェント構築は AIエージェント 作り方、RAG は RAG とは、AI コーディング全体地図は AI コーディング で別建てしています。
ローカル LLM はモデル更新が非常に速く、本記事の数字・モデル名・ライセンスはすべて 2026 年 5 月時点です。最新の状況は各モデル公式(Meta / Mistral AI / Google / Alibaba / DeepSeek / Microsoft)と Hugging Face で必ず事前確認してください。
LLM ローカルとは——クラウド AI との 4 つの違い
📖 この章で使う用語
- OSS LLM(Open Source Software LLM):ソースコードとモデル重み(weights)が公開されている LLM。Llama / Mistral / Gemma が代表例。
- プロプライエタリ LLM:開発元が内部仕様を非公開にしている商用 LLM。GPT 系 / Claude 系 / Gemini 系が代表例。
- モデル重み(weights):LLM が学習で身につけた「言葉の関係性の数値」の一式。ダウンロードできる「LLM 本体ファイル」のイメージ。
- 推論(inference):学習済みモデルに文章を渡して、応答を生成させる処理。「AI に質問して回答をもらう」その瞬間の計算。
LLM 自体の基本概念があやふやな方は LLM とは を先にご覧ください。クラウド AI(ChatGPT / Claude / Gemini)とローカル LLM の違いは、次の 4 点に集約できます。
① モデルが置かれている場所:クラウド AI は運営会社のサーバ上にモデルがあり、手元には何もダウンロードされません。ローカル LLM はモデル本体(数 GB 〜 数十 GB)を自分の PC に置きます。
② 推論計算が走る場所:クラウド AI は運営会社のサーバ側で推論(GPU / TPU の重い処理)が走ります。ローカル LLM は自分の PC の CPU / GPU で走ります。
③ インターネット接続:クラウド AI は必須で、回線が落ちると使えません。ローカル LLM は一度落とせばオフラインで動き、飛行機内・出張先の不安定 WiFi・社内 VPN 縛りで出番になります。
④ 月額課金:クラウド AI は従量課金または月額サブスク(ChatGPT Plus / Claude Pro 等)。ローカル LLM は一度動けばランニング費用ゼロ(ハードウェア代と電気代を除く)。
たとえるなら クラウド AI = レンタル車、ローカル LLM = 自家用車。どちらが優れているではなく、用途で使い分けるのが現実的です。
もう 1 つ欠かせない区別が OSS LLM とプロプライエタリ LLM です。ローカル LLM として動かせるのは基本的に OSS LLM——つまり、開発元がモデル重みを公開しているモデルだけです。Llama(Meta)、Mistral(Mistral AI)、Gemma(Google)、Qwen(Alibaba)、DeepSeek(DeepSeek 社)、Phi(Microsoft)が代表例です。一方、GPT 系・Claude 系・Gemini 系はプロプライエタリ LLM——モデル重みは非公開で、利用者は API 越しにしかアクセスできません。「クラウド AI のフロンティアモデルを、そっくり同じ性能で自分の PC で動かす」ことはできない——これは 2026 年 5 月時点の現実です。
2026 年 5 月時点の業界動向としては、OSS LLM の性能はクラウドのフロンティアモデルに着実に追いついてきており、用途を絞れば実用レベルの差は縮まっています。LMSYS Chatbot Arena(人間評価ベースのモデル比較)でも、Llama 3 系統や Qwen 系統は GPT-4 系列に肉薄するスコアを記録しています(最新ランキングは lmarena.ai で必ずご確認ください)。とはいえ、汎用的な業務本番運用の主力としては、まだクラウド API が現実解という整理が、私の業務感覚と公式の評価データの双方から見える 2026 年 5 月時点の姿です。
ローカル LLM 5 つのメリット——プライバシー / オフライン / 無料 / カスタマイズ / 学習目的
📖 この章で使う用語
- オフライン動作:インターネット接続なしで動くこと。出張・飛行機内・社内 VPN 環境で重要。
- 量子化(Quantization):モデルの数値精度を落としてサイズを小さくする技術。4-bit / 5-bit / 8-bit が代表的。
- ファインチューニング(fine-tuning):既存モデルに追加学習させて特定用途に最適化する操作。
- LoRA(Low-Rank Adaptation):ファインチューニングの軽量手法。少ない計算量で挙動を変えられる。
ローカル LLM の 5 つのメリットを順に整理します。自分の Mac で触った範囲と、公式情報や評判をまとめた範囲が混ざる点を先にお伝えします。
メリット ① プライバシー:データが手元から出ない
これが最大のメリットです。クラウド AI に質問すると、入力した文章(社内コード・顧客情報・契約書ドラフトなど)が運営会社のサーバを経由します。多くの事業者は「API の入力データは学習に使わない」と公表していますが、それでも「社外に出すこと自体が抵抗ある」「社内規定で外部 AI 入力が禁止」というケースは少なくありません。ローカル LLM なら入力も出力もすべて自分の PC で完結し、ネットには 1 バイトも流れません。社内コード整形・顧客リストの下処理・契約書校正など「外に出したくないデータの AI 処理」の現実解になります。社内コードを外部に送れない環境での Ollama + Code Llama / DeepSeek Coder は AI コードレビュー のセクション 7 でも扱っています。
メリット ② オフライン動作:ネット環境を選ばない
飛行機内・新幹線のトンネル・遅いフリー WiFi・社内 VPN 縛り——クラウド AI が使えない環境でも、ローカル LLM はネット接続ゼロで動きます。私も機内モードの MacBook Pro で Ollama + Llama 3 を動かし、簡単な文章整形やコードの読み解きをさせた経験があります。
メリット ③ 無料:ハードウェア代を除けば月額課金ゼロ
クラウド AI は従量課金または月額サブスク(ChatGPT Plus / Claude Pro が月 20 ドル前後)で固定費が発生します。ローカル LLM は一度動けば API 課金はゼロ(電気代と PC のメンテ費は別途)。コストを固定費化したい学習・趣味・個人ブログ用途では選択肢になります。ただし初期費用としてある程度のスペックを持つ Mac / PC が必要な点には注意してください。
メリット ④ カスタマイズ性:量子化・LoRA・ファインチューニング
モデル本体を手元に持つ強みで、カスタマイズの自由度が高い です。
- 量子化(Quantization):数値精度を 4-bit / 5-bit / 8-bit に落としてサイズと計算量を下げる
- LoRA(Low-Rank Adaptation):少ない計算量で自社データや特定用途に挙動を微調整する
- フルファインチューニング:大規模に追加学習させ特定領域(医療・法務・社内 FAQ など)に特化させる
クラウド AI もファインチューニングを提供しますが、ローカルの自由度はそれを超えます。ただし業務本番に乗せる場合はモデル品質の劣化・データセット作成負担・運用保守の人手が必要で、本項は公式情報や評判をもとにした紹介です。
メリット ⑤ 学習目的:AI の中身を体感で理解できる
これから生成AIエンジニアを目指す方には、いちばん地味だが大きいメリットです。手元で動かすと AI の物理的な実体が見えてきます——モデルサイズが何 GB か、量子化で何 GB に縮むか、推論に何秒かかるか、RAM や GPU をどれだけ食うか。API 越しでは見えない部分が手元で確認でき、クラウド AI を使うときに中で何が起きているかを立体的に理解できるようになります。
ローカル LLM 5 つのデメリット——性能 / スペック / セットアップ / モデル更新 / 商用利用ライセンス
📖 この章で使う用語
- ベンチマーク:LLM の性能を測る統一指標。LMSYS Chatbot Arena / HuggingFace Open LLM Leaderboard が代表例。
- モデル更新サイクル:LLM のバージョンアップ頻度。クラウド AI は運営側が自動更新、ローカル LLM は利用者が手動で追従。
- 商用利用ライセンス:そのモデルを商用で使ってよいかの法的条件。モデルごとに異なる。
デメリットも 5 つ正直に書きます。メリット側と見比べると、自分にとって現実解かが立体的に判断できます。
デメリット ① 性能差:フロンティアモデルとはまだ差がある
2026 年 5 月時点、クラウド最先端モデル(GPT-5 系列 / Claude Opus 4.6 / 4.7 / Gemini Ultra 2 等)と、ローカル OSS LLM の最高峰(Llama 3.1 70B / Mixtral 8x22B 等)には、まだ性能差があります。公開ベンチマーク(lmarena.ai / Hugging Face Open LLM Leaderboard)でもフロンティアモデルが上位です。ただし全用途で差があるわけではなく、コード補完・英文要約・定型的な文章整形などでは Llama 3 8B クラスでも実用十分です。「フロンティアモデルの代替」ではなく「用途を絞った相棒」が現実的な立ち位置です(モデルの選び方は Claude Opus)。
デメリット ② ハードウェア要件:それなりのスペックが要る
一定以上の RAM・VRAM・GPU が必要で、メモリ 8 GB クラスや古いノート PC では量子化モデルでも厳しい場合があります。Apple Silicon Mac なら用途とモデルサイズで 16 GB / 32 GB / 64 GB を分けて選びます(詳細は ハードウェア要件)。
デメリット ③ セットアップ負担:環境構築と量子化選定の学習コスト
クラウド AI はブラウザでサインアップすれば即使えますが、ローカル LLM は Ollama / LM Studio などを入れ、モデルをダウンロードし、量子化版(Q4_K_M / Q5_K_M / Q8_0 等)を選び、CLI かアプリで動かす流れです。慣れれば 5 分ですが、最初は CLI 操作やファイルパスで躓きやすい領域です。生成AIエンジニアを目指す方には、この「セットアップ自体が学習機会」になる側面もあります。
デメリット ④ モデル更新:自分で追従する手間
クラウド AI は運営側が自動更新しますが、ローカル LLM は新モデルが出るたび自分で ollama pull llama3.2 を打ち、古いモデルを整理する運用が要ります。常に最新を追いたい場合、この手間が地味に重いのが実務上の悩みです。
デメリット ⑤ 商用利用ライセンス:モデルごとに条件が違う
最も注意が必要なデメリットです。OSS LLM でも何でも自由に商用利用できるわけではありません。Llama 系は Llama 3 Community License で月間アクティブユーザー 7 億人超の企業は別途許諾が必要、Mistral は Apache 2.0 と独自ライセンスが混在、Gemma は Gemma Terms of Use、Qwen / DeepSeek もそれぞれ独自条項です。商用利用を検討する場合、(1) ライセンス条項を公式で確認、(2) 社内法務・コンプライアンス部門に相談、(3) 必要に応じて弁護士に相談——の 3 ステップを踏んでください。本項は公式情報をもとにした注意喚起です。
業務本番運用のメインはクラウド API(Claude 使い方 / ChatGPT 始め方 / AWS Bedrock)で、ローカル LLM は機密性・コスト最適化・オフライン要件のある特定用途で「組み合わせる」のが現実解です。
ハードウェア要件と量子化|Apple Silicon の統合メモリ・16/32/64GB の使い分け・Windows GPU

📖 この章で使う用語
- Apple Silicon:Apple が自社設計した Mac 用 CPU 系列(M1 / M2 / M3 / M4)。CPU・GPU・メモリが 1 チップに統合されている。
- 統合メモリ(Unified Memory):Apple Silicon の特徴で、CPU と GPU が同じ RAM を共有する設計。LLM 推論で VRAM ボトルネックが緩和される。
- Metal:Apple の GPU プログラミング API。Ollama などが Mac で GPU 加速するのに使う。
- VRAM(Video RAM):GPU 専用メモリ。LLM をローカルで動かすときに「載るか/載らないか」を決める要素。
- 量子化版(4-bit / 5-bit / 8-bit):モデルサイズを下げて RAM / VRAM 要件を緩める版。Q4_K_M / Q5_K_M / Q8_0 等の表記。
Apple Silicon Mac 中心 に解説します。私の業務 PC が MacBook Pro で、Ollama を触ったのも Mac M シリーズの環境だからです。Windows + NVIDIA GPU は使っていないため公式情報をもとに並列で扱います。
Apple Silicon Mac の Metal アクセラレーション(統合メモリの強み)
Apple Silicon Mac(M1 / M2 / M3 / M4)には、ローカル LLM 用途で 2 つの大きな強みがあります。
① 統合メモリアーキテクチャ:通常のデスクトップ PC は CPU と GPU が別々のメモリ(システム RAM と VRAM)を持っており、LLM をロードするときに「VRAM に収まるか」が大きな制約になります。たとえば NVIDIA RTX 3060 の VRAM は 12 GB ですが、8 GB を超える量子化モデルはそのままでは載りません。
Apple Silicon は逆で、CPU と GPU が 同じ RAM を共有 します。たとえば 32 GB RAM の MacBook Pro なら、その 32 GB を CPU と GPU が状況に応じて分け合います。VRAM ボトルネックがなく、システム RAM の容量がそのまま LLM のロード上限になります。Llama 3 70B の量子化版(約 40 GB)を動かすのに、64 GB RAM の Mac Studio なら 1 台でロードできる、というのが大きな違いです。
② Metal アクセラレーション:Apple 独自の GPU API「Metal」で、Ollama や llama.cpp は Mac の GPU を使って推論を加速します。CPU だけより数倍速くなるのが標準的な体感です。
私の個人検証では、MacBook Pro M シリーズ + 32 GB RAM で Llama 3 8B の量子化版(Q4_K_M、約 5 GB)が、応答開始まで 1-2 秒、生成速度は毎秒 20-40 トークン程度でした。クラウド AI(GPT-4 / Claude Opus で毎秒 30-60 トークン前後)と比べても、量子化した小型モデルなら十分「使える速度」です。
メモリ推奨(16GB / 32GB / 64GB の使い分け)
RAM 容量別の現実的な目安です(用途・モデルサイズ・並行作業で振れます)。
| RAM | 動くモデルの目安 | 向くフェーズ |
|---|---|---|
| 16 GB | Llama 3 8B / Gemma 7B / Mistral 7B クラスの量子化版(Q4_K_M、約 4-5 GB) | 感触を掴む入門段階の最小構成。エディタ併用でも軽い整形・読み解きは実用速度 |
| 32 GB | 13B クラス(Llama 2 13B 等)が快適。70B は強い量子化で動くが速度は落ちる | 文章生成・コード生成・社内 RAG 検証など複数用途の個人検証にバランスがいい |
| 64 GB 以上 | Llama 3.1 70B / Mixtral 8x22B クラスの量子化版 | 本格運用や社内 PoC。Mac Studio / 上位 MacBook Pro が必要で価格も上がる |
私自身が使い込んだのは 32 GB クラスまでで、70B クラスの本格運用は公式情報をもとにした紹介です。なお、LLM だけでなく画像・動画生成までローカルで視野に入れる場合はメモリの効き方が変わります(LLM は常駐で効き、画像・動画は生成のピークで落ちる)。その帯別の考え方は ローカル生成AI に必要なスペック に M1 Max 32GB の実測から逆算してまとめました。
Windows + NVIDIA GPU の場合
業務 PC が Mac のため使い込んでいませんが、公式情報をもとに整理します。NVIDIA GPU の VRAM 容量が、動かせるモデルサイズを直接決めます(2026 年 5 月時点の目安):
- VRAM 8 GB(RTX 3060 等):7B クラスの量子化版が動く下限ライン
- VRAM 12 GB(RTX 3060 12GB / RTX 4070 等):7-13B クラスの量子化版が快適
- VRAM 24 GB(RTX 3090 / RTX 4090 等):13-30B クラスや、70B クラスの強い量子化版
Apple Silicon の統合メモリと違い、Windows + NVIDIA GPU では VRAM が明確なボトルネックです。VRAM を超えるモデルは CPU 側のシステム RAM にオフロードされ、速度が大きく落ちます。最新の機種別ベンチマークは Ollama 公式などでご確認ください。
量子化(4-bit / 5-bit / 8-bit)でモデルサイズを下げる
LLM のモデル重みは本来 16-bit / 32-bit の浮動小数点で記録されています。これを低精度に圧縮するのが量子化です。Llama 3 8B の元データ(16-bit、約 16 GB)は 4-bit 量子化版(Q4_K_M)で約 4.7 GB になります。RAM / VRAM 要件が約 1/4 になる代わり、応答品質が少しずつ落ちるトレードオフです。
- Q4_K_M(4-bit):サイズ最小、品質は実用ライン。入門段階の標準
- Q5_K_M(5-bit):Q4 より少し大きく、品質はやや向上
- Q8_0(8-bit):元データに近い品質、サイズは Q4 の約 2 倍
まず Q4_K_M で動かし、品質に不満を感じたら Q5 / Q8 に上げる順序が現実的です。
なお、「自分の Mac で足りるのか、買うなら結局どの Mac を選べばいいのか」を予算・メモリ別に詳しく知りたい方は、ローカルLLM 向け Mac の選び方 に、16GB / 32GB / 64GB+ の用途別の選び方をまとめました。
主要モデル一覧——Llama / Mistral / Gemma / Qwen / DeepSeek / Phi の俯瞰
📖 この章で使う用語
- Llama(ラマ):Meta(旧 Facebook)が公開している OSS LLM の代表。
- Mistral(ミストラル):フランスの AI 企業 Mistral AI が公開している OSS LLM。
- Gemma(ジェマ):Google が公開している OSS LLM。Gemini 系の研究を OSS 化した位置づけ。
- Qwen(クウェン):Alibaba が公開している OSS LLM。多言語対応に強み。
- DeepSeek(ディープシーク):DeepSeek 社が公開している OSS LLM。コード特化版(DeepSeek Coder)も人気。
- Phi(ファイ):Microsoft が公開している小規模・高効率 OSS LLM。
- パラメータ規模:LLM が覚えている「言葉と言葉の関係の数値」の総数。7B(70 億)/ 13B / 70B のように表記。
6 系統のモデルファミリー を俯瞰します。経験範囲は、Llama 3 8B / Code Llama / DeepSeek Coder を Ollama で個人検証、Mistral / Gemma / Qwen / Phi は公式ドキュメントとベンチマークをもとに紹介、いずれも業務本番運用には乗せていません。
迷ったときの一行マップは 「まず Llama 3 8B か Gemma 7B」。両方とも量子化版で 16 GB RAM の Mac で動き、日本語にもある程度対応します。
Meta Llama 系(Llama 3 / Llama 3.1 / Code Llama)
Meta(Facebook の親会社)が公開している OSS LLM の代表格です。2026 年 5 月時点で、Llama 3 / Llama 3.1 / Llama 3.2 系列があり、パラメータ規模は 8B / 70B / 405B のレンジでリリースされています。
- Llama 3 / 3.1 8B:ローカル LLM の標準モデル。量子化版で 5 GB 前後、16 GB RAM の Mac で動く
- Llama 3.1 70B:高品質、64 GB RAM 推奨。量子化を強くかければ 32 GB でも動かせる
- Code Llama:コード特化版、AI コードレビュー のセクション 7 で詳述
商用利用ライセンスは Llama 3 Community License で、月間アクティブユーザー 7 億人を超える企業は別途許諾が必要、という条項があります(2026 年 5 月時点、最新条項は llama.com で必ずご確認ください)。中小規模の用途では実質的に自由に商用利用できる、というのが一般的な理解です。
Mistral 系(Mistral 7B / Mixtral 8x7B / Mixtral 8x22B)
フランスの AI 企業 Mistral AI が公開している OSS LLM。英語性能の高さとライセンスの寛容さ で人気があります。
- Mistral 7B:7B クラスの代表的選択肢、Apache 2.0 ライセンス、商用利用も比較的自由
- Mixtral 8x7B / 8x22B:Mixture of Experts(MoE)アーキテクチャで、実効パラメータが大きい
- 一部の最新モデルは Mistral 独自ライセンスに移行している部分もあり、商用利用前に必ず公式(mistral.ai)でご確認ください
Mistral 系は手元で長時間動かし込んでおらず、公式ドキュメントとベンチマークをもとにした紹介です。
Google Gemma 系(Gemma / Gemma 2 / CodeGemma)
Google が公開している OSS LLM。Gemini 系の研究を OSS 化した位置づけで、2B / 7B / 9B / 27B クラスのモデルがリリースされています。
- Gemma 7B / Gemma 2 9B:7-9B クラスの選択肢、Apple Silicon Mac 16 GB で動く
- CodeGemma:コード特化版
- ライセンスは Gemma Terms of Use(Apache 2.0 とは異なる Google 独自条項)。商用利用前に必ず公式(ai.google.dev/gemma)でご確認ください
Llama 3 8B と Gemma 7B を並行して触った範囲では、日本語応答の品質に個体差があり、用途で使い分けるのが現実的でした。
Qwen / DeepSeek / Phi 系(多言語・コード特化・小規模高効率)
最後に 3 系統まとめて整理します。
- Qwen(Alibaba):中国語・日本語など多言語に強い OSS LLM。Qwen 2.5 系列は 0.5B / 1.5B / 7B / 14B / 32B / 72B クラスがあり、ライセンス条件はモデルサイズで異なります(公式 qwen.io で必ずご確認ください)。日本語性能の評判が高いと言われることも多い系統です
- DeepSeek(DeepSeek 社):コード特化版 DeepSeek Coder が人気。AI コードレビュー のセクション 7 で詳述しています
- Phi(Microsoft):Phi-3 / Phi-3.5 系列は、小型サイズ(3.8B / 7B / 14B)でも高品質を狙う設計。学術用途やエッジデバイスでの利用が想定された系統です
これら 3 系統は手元で長時間動かし込んでおらず、公式情報をもとにした紹介です(自分で動かし込んだのは Llama 3 / Code Llama / DeepSeek Coder)。フロンティアモデルと OSS LLM の性能差は縮まり続けていますが、汎用的な業務本番運用としてはまだクラウド API が現実解、というのが私の業務感覚です。
日本語対応モデル——Llama-3-ELYZA-JP / Swallow / Qwen / Gemma の整理

📖 この章で使う用語
- 継続学習(Continual Pretraining):既存の英語ベース LLM に日本語データを追加学習させる手法。
- Llama-3-ELYZA-JP:ELYZA 社が Llama 3 をベースに日本語追加学習させた OSS LLM。
- Swallow:東京工業大学等が継続学習で日本語化した OSS LLM 系列。
SERP 上位の記事は英語モデル一色になりがちで、日本語対応モデルの整理は手薄な領域です。前置きとして、私の日本語業務処理のメインは Claude / ChatGPT / Gemini の API で、ローカルの日本語特化モデルは使い込んでいないため、本章は公式情報や評判をもとに紹介します。用途と最新リリースで揺れる領域なので、Hugging Face で最新状況をご確認ください。
Llama-3-ELYZA-JP:日本企業発の日本語追加学習モデル
ELYZA 社(日本企業)が Llama 3 をベースに日本語データで継続学習させた OSS LLM です。Llama-3-ELYZA-JP-8B などのモデルが Hugging Face で公開されており、日本語タスクでの評価が高いと言われることが多い系統です(最新リリースは huggingface.co/elyza で必ずご確認ください)。
商用利用は Llama 3 のライセンス条項を継承するため、Meta の Community License に従う必要があります。ELYZA 社独自の追加条項がある可能性もあるため、公式の利用条件を必ずご確認ください。
Swallow:日本の大学発の継続学習モデル
東京工業大学(現・東京科学大学)と国立情報学研究所(NII)等の共同研究で開発された日本語特化 OSS LLM 系列です。Llama や Mistral などのベースモデルに日本語データで継続学習させたモデル群(Swallow / Swallow-MS など)が公開されています。
学術機関発のため、研究目的・教育目的での利用は比較的自由ですが、商用利用にはベースモデルのライセンス条項(Llama Community License や Apache 2.0 など)が適用されます。最新条件は huggingface.co/tokyotech-llm で必ずご確認ください。
Qwen:多言語対応で日本語性能も高評価
Alibaba が公開する Qwen 系列は、中国語をベースに多言語対応を強みとしており、日本語タスクの性能も高く評価されることがあります(最新ベンチマークは公式 qwen.io と LMSYS Chatbot Arena で必ずご確認ください)。Qwen 2.5 系列は 0.5B から 72B まで幅広いサイズ展開があり、用途に応じて選びやすい系統です。
ライセンス条件はモデルサイズと用途で異なる点に注意が必要です。商用利用前に必ず公式でご確認ください。
Gemma:Google 製の日本語対応 OSS LLM
Google の Gemma 系列も、Gemini で培われた多言語データを反映しており、日本語応答の品質は評価される系統の 1 つです。Gemma 2 9B は Apple Silicon Mac 16 GB の量子化版で実用速度が出る目安、というのが Ollama 公式情報からの整理です。
日本語モデルの選び方ガイド
日本語対応ローカル LLM を選ぶ際の整理軸は 3 つです。
- 業務用途の機密性:機密情報を含む日本語処理なら、社内ネットワーク内で完結するローカル日本語モデルが選択肢
- パラメータ規模と PC スペック:16 GB なら 7-9B、32 GB なら 13B、64 GB なら 70B クラス(量子化前提)
- ライセンス条項:商用利用前に必ず公式とライセンス全文をご確認ください
最新のリリース動向は huggingface.co の各組織アカウントで継続的にご確認いただくのが現実的です。
構築ツール 4 種——Ollama / LM Studio / llama.cpp / GPT4All の俯瞰
📖 この章で使う用語
- Ollama(オラマ):手元 PC で OSS LLM を動かす最も簡単なツール。CLI ベース。
- LM Studio:GUI(画面操作)で LLM を動かせるアプリ。初心者向け。
- llama.cpp:C++ で書かれた最も低レイヤーの推論エンジン。量子化の自由度が高い。
- GPT4All:GUI ベースの LLM 実行ツール。複数モデル管理機能あり。
- CLI(Command Line Interface):パソコンに文字でコマンドを打って指示を出す画面。営業時代の私は「真っ黒な怖い画面」だと思っていました。
ローカル LLM を動かすツールを 4 種類俯瞰します。「迷ったらまず Ollama」 が入門段階の一行マップです。
Ollama:CLI ベース、最も簡単
私の個人検証で使ったのが Ollama です。brew install ollama でインストール、ollama pull llama3 / ollama run llama3 でモデルを動かせます。CLI ですが慣れれば最速。強みは (1) インストールが 1 行、(2) モデル管理が ollama pull で完結、(3) REST API がデフォルトで立つ(ポート 11434)、(4) Python / JavaScript クライアントが充実、の 4 点です。最初に触るツールとしては遠回りが少ない選択肢です。AI コードレビュー のセクション 7 では Ollama + Code Llama / DeepSeek Coder を扱い、本記事は Llama 3 / Gemma 中心で分担しています。
LM Studio:GUI ベース、初心者向け
ブラウザのような GUI で LLM を動かせるアプリです。Hugging Face のモデルを画面から検索・ダウンロードでき、チャット画面も内蔵。「CLI に抵抗がある」方向けの選択肢です。私は使い込んでおらず、本項は LM Studio 公式(lmstudio.ai)をもとにした紹介です。なお 2026 年 7 月には、同じ開発元から資料作成やコード修正を任せられる AI エージェントの別アプリ LM Studio Bionic も登場しています。
llama.cpp:最も低レイヤー、量子化の自由度が高い
Ollama や LM Studio の 裏側で動く推論エンジン です。C++ 製で、量子化や実行時パラメータの自由度がいちばん広い選択肢です。ただし CLI 習熟がそれなりに要り、入門段階には学習コストが高め。Ollama / LM Studio に慣れた後、量子化を細かく調整したい段階で降りていく順序が一般的です。
GPT4All:GUI ベース、複数モデル管理
複数モデルを 1 つのアプリで管理できる GUI ツールです。LM Studio に近い操作感の初心者向け選択肢。私は使い込んでおらず、GPT4All 公式(gpt4all.io)をもとに紹介します。
結論:迷ったらまず Ollama、慣れたら幅を広げる
入門段階は Ollama、画面操作派は LM Studio、自由度を求める段階は llama.cpp——というのが現実的な順序です。
5 分で動かす最小手順|Ollama インストール・モデル取得・CLI チャット・Python から呼び出し
📖 この章で使う用語
- Homebrew(ホームブリュー):macOS でコマンドラインアプリを管理するパッケージマネージャ。
brew installで 1 行インストール。- REST API:プログラムから他プログラムを呼び出すための標準的なインターネット越しの仕組み。Ollama はデフォルトで
http://localhost:11434に立つ。- localhost(ローカルホスト):自分の PC 自身を指すアドレス。インターネットに出ずに、PC 内部で完結する通信。
Mac M シリーズで Ollama + Llama 3 / Gemma を 5 分で動かす最小手順 を 5 ステップで整理します。業務本番運用の推奨ではなく、感触を掴むための最小動線 です。私の個人検証で実際に動かしている手順をベースに書きます。
ステップ ①:Homebrew で Ollama をインストール
Mac で Homebrew が既に入っている前提で、次の 1 行でインストールします。
# Mac M シリーズ前提(Apple Silicon)
brew install ollamaHomebrew が入っていない場合は、まず https://brew.sh の指示に従って Homebrew を導入してください。Apple Silicon Mac なら標準で対応しています。
ステップ ②:Ollama サーバーを起動
インストールが終わったら、Ollama サーバーを起動します。
# Ollama サーバーを起動(バックグラウンドで動き続ける)
ollama serve別のターミナルウィンドウを開いて、次のステップに進んでください。サーバーは http://localhost:11434 で待ち受けます。サーバーを起動しなくても ollama run コマンドで自動的に立ち上がる場合もあります(OS とバージョンに依存)。
ステップ ③:Llama 3 / Gemma をダウンロード
サジェストされた 2 つのモデルから、お好きな方をダウンロードします。
# Llama 3 8B(量子化版、約 5 GB)をダウンロード
ollama pull llama3
# Gemma 7B(量子化版、約 5 GB)をダウンロード
ollama pull gemma:7bダウンロードには、回線速度に応じて 5-15 分程度かかります。一度落とせば、以降は手元のディスクから即時起動します。
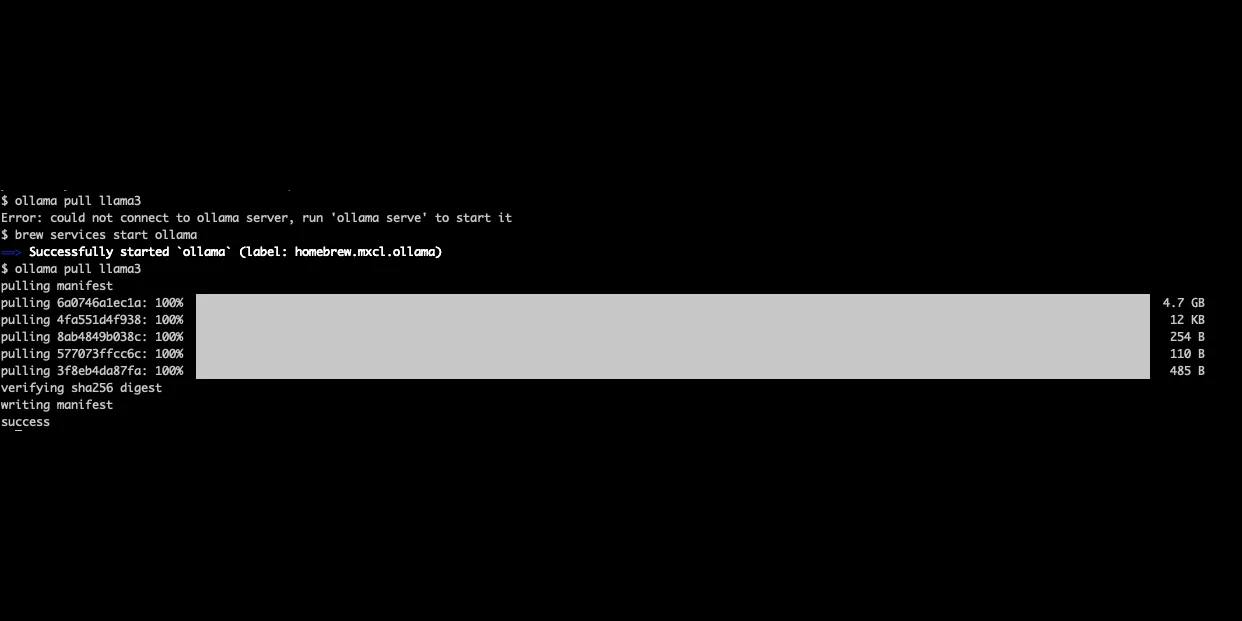
実際に手元の Mac で ollama pull llama3 を実行した画面が次です。約 4.7GB の量子化モデルがダウンロードされ、最後に success と表示されています(Ollama サーバーは brew services start ollama で起動しています)。
ステップ ④:CLI でチャット
ダウンロードが完了したら、CLI から対話できます。
# Llama 3 とチャット(対話モード)
ollama run llama3
# Gemma とチャット
ollama run gemma:7b>>> プロンプトが出たら、自由に質問を打ち込んでください。終了するには /bye か Ctrl+D で抜けます。
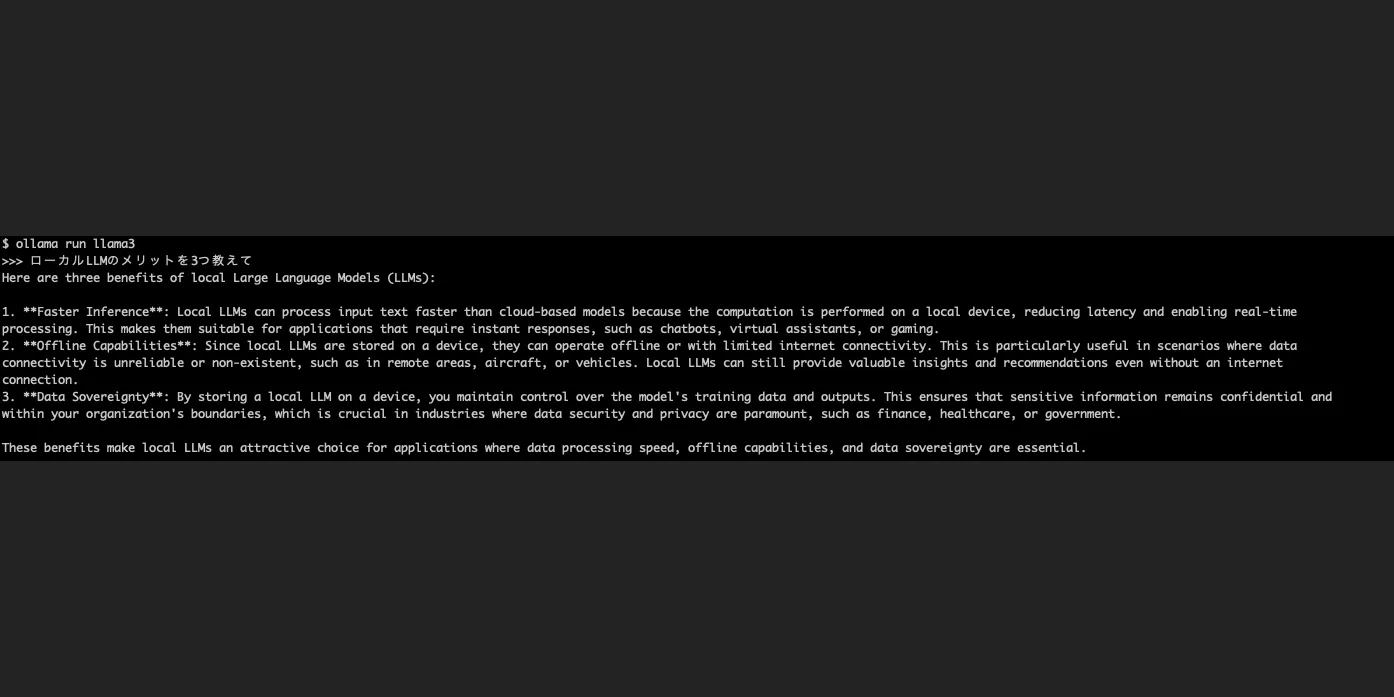
実際に ollama run llama3 を起動し、日本語で「ローカルLLMのメリットを3つ教えて」と尋ねた画面が次です。クラウドに送らず、PC の中だけで回答が返ってきています。なお llama3 は英語が得意なモデルなので、日本語で尋ねても回答は英語で返ってきました(日本語が得意なモデルを使いたい場合は日本語対応モデルを参照してください)。
ステップ ⑤:Python から REST API で呼び出し
最後に、Python プログラムから Ollama を呼び出す最小コードです。Ollama は REST API(HTTP)で動くため、Python の標準ライブラリでも叩けますし、ollama という Python ライブラリも公式に提供されています。
# Ollama 公式 Python ライブラリでの最小呼び出し
# pip install ollama でインストール
import ollama
response = ollama.chat(
model='llama3',
messages=[
{'role': 'user', 'content': 'ローカル LLM のメリットを 3 つ教えてください'}
]
)
print(response['message']['content'])これで Python プログラムからローカル LLM を呼び出せます。RAG / エージェント / 業務スクリプトに組み込む土台ができた状態です。なお本手順は感触を掴むための最小動線で、業務本番運用に進む場合は (1) モデルライセンスの再確認、(2) 社内コンプライアンス部門との合意、(3) 性能・可用性・運用負担の事前検証、の 3 ステップが必須です。
ここまでで「文章の LLM」は動きました。同じ Mac で 画像生成側(ComfyUI) も動かしてみたい方は、ComfyUI を Mac で始める手順 に、導入後につまずきやすい地雷(モデルの置き場所・容量枯渇など)まで含めた時系列の手順をまとめています。なお Ollama 自体も 2026 年 1 月から macOS で画像生成に試験対応しました(Windows・Linux は未対応)。まず 1 枚出すだけなら Ollama で足り、その先で ComfyUI が要る——という線引きは ローカルLLM 画像生成 に整理しています。
用途別おすすめ——コード生成 / 文章作成 / RAG / エージェント / 小説の 5 用途
📖 この章で使う用語
- RAG(Retrieval-Augmented Generation:検索拡張生成):LLM の応答に「外部ドキュメント検索結果」を組み合わせる手法。詳しくは RAG とは で扱っています。
- ベクトル DB:意味が近いものを素早く取れる DB。FAISS / Chroma / Weaviate が代表例。
- AIエージェント:自分で計画を立てて、ツールを使い分けながらタスクをこなす AI。詳しくは AIエージェント 作り方 で扱っています。
ローカル LLM の 5 つの代表用途を整理します。自分で触った範囲と、公式情報や評判をまとめた範囲が混ざります。
コード生成・レビュー → Code Llama / DeepSeek Coder
ローカル LLM の代表用途の 1 つが、コード生成とコードレビューです。Code Llama(Meta)と DeepSeek Coder(DeepSeek 社)は、コードに特化して学習された OSS LLM で、Apple Silicon Mac 16 GB 環境でも量子化版が動きます。
詳しくは AI コードレビュー のセクション 7 「ローカル LLM でのコードレビュー」で別建てしているので、本記事では概観のみに留めます。社内コードを外部に出せない環境で、AI コードレビューを試したい場合の有力な選択肢です。AI コーディングの全体像は AI コーディング でも俯瞰しています。
文章作成・要約・校正 → Llama 3 / Gemma / Qwen
汎用的な文章作成・要約では、Llama 3 8B / Gemma 7B / Qwen 2.5 7B のいずれかから入るのが現実的です。私の個人検証では、英語文章は Llama 3、日本語文章は Gemma または ELYZA-JP という使い分けが落ち着きました。
なかでも 文章校正 はローカル LLM の利点が出やすい用途です。誤字脱字チェック・冗長表現の言い換え・トーン調整は、社外に出せない契約書ドラフト・人事文書・顧客メールなどをクラウドに貼らずに手元で回せます。込み入った文脈理解や長文の一貫性はクラウド API に分があるため、機密文書の一次校正はローカル、最終仕上げは用途に応じて という使い分けが現実的です。
校正プロンプトの型:ローカル LLM は指示がゆるいと校正を超えて勝手にリライトし、元の意味まで変えがちです。誤字脱字・助詞の誤り・冗長表現だけを直してください。意味と語順は変えず、修正した箇所は一覧で示してください のように 「直す範囲」と「触らない範囲」を明示する と扱いやすくなります。トーン調整は「丁寧語に統一」「結論を先に」のように 1 回 1 観点に絞ると安定します。
校正でのつまずき 3 つ:(1) 量子化を強くかけると日本語の漢字変換・敬語の精度が落ち、校正のはずが新しい誤りを増やすことがある(校正用途では量子化を欲張らない方が無難)。(2) 制約を書かないとモデルが勝手に内容を補完・創作する(上の型で抑える)。(3) 長文を一度に投げると後半で最初の指示を忘れがち(段落単位で渡すと安定)。いずれも機密性とのトレードオフです。
文章校正が主目的の方へ:社外秘を外に出さず手元で直す校正プロンプトの 4 観点・精度の限界・クラウド AI 校正との使い分けを、実際に手元の Ollama で自分の文章を校正させて深掘りした専用スポークを別に用意しています。ローカルLLM 文章校正の現実|社外秘を出さず手元で直す をご覧ください。本章ではそのエッセンスだけをまとめています。
RAG(社内検索)→ Llama 3 + FAISS / Chroma
社内ドキュメント検索を AI 化する RAG では、ローカル LLM + ベクトル DB が機密情報を外に出さず動かせる構成として注目されています(概念は RAG とは、本記事は構成例の俯瞰のみ)。私の業務 RAG はクラウド API + ベクトル DB(FAISS / Chroma / Weaviate)が主軸で、ローカル LLM の RAG は個人検証レベルです。業務本番に乗せる場合は推論速度・モデル品質・運用負担の 3 つの壁を事前検証してください。
AIエージェント → ローカル LLM + LangChain
ローカル LLM を AIエージェントの推論エンジンに使う選択肢もあります。LangChain / LangGraph などのフレームワーク経由でプラグインできます。詳しいエージェント構築は AIエージェント 作り方 で別建てしており、ローカル LLM ルートは個人検証レベルとして扱われています。
小説・創作系 → 詳しくは次の小説・創作系のユースケースで深掘り
本記事の差別化軸の 1 つで、SERP 上位の記事はほぼ触れない論点です。詳しくは 小説・創作系のユースケースで深掘りします。
小説・創作系のユースケース——クラウド AI が拒否しがちな表現でも、ローカルなら自由度高い

📖 この章で使う用語
- コンテンツモデレーション(content moderation):AI 出力が不適切な内容を含まないかチェックする機能。クラウド AI に内蔵。
- 拒否回答(Refusal):AI が「お答えできません」と返す挙動。クラウド AI の安全装置の 1 つ。
環境を作った次の題材として、小説は成果が目に見えやすい用途です。まず数百字の場面を無料の手順で試し、さらに第1話を通す工程まで見たい場合は、筆者が実際に初稿→ダメ出し→リテイクを記録したガイドを選べます。¥980で、環境構築の章までは note で無料試し読みできます(価格・内容の最新情報は note でご確認ください)。
📖 小説用途を本気で検討する方へ(深掘りスポーク) 本章は親ハブ側の要点整理です。向くモデルの系統・プロンプト設計の型・長文の一貫性の壁・著作権と規約の 4 点まで独立して掘り下げた専用記事を別に用意しています。小説生成が主目的の方は ローカルLLM 小説の現実|向くモデル・長文の壁・著作権まで整理 をご覧ください。本章ではそのエッセンスだけをまとめます。
なぜローカル LLM が小説生成で言及されるのか
クラウド AI はコンテンツモデレーションが組み込まれており、暴力描写・性表現・差別表現を含む小説的な文章では拒否回答(「お答えできません」)が返ることが知られています。一方ローカル LLM はモデルが手元にあるため、モデルライセンスと配布元の利用条件が許す範囲で、コンテンツモデレーションを自分の責任で外せる場合があります。文学的表現の自由度を保ちたい創作者・小説家・脚本家の間で選択肢として挙げられます。
日本語小説生成で挙げられる系統
日本語小説生成では、日本語特化モデル(Llama-3-ELYZA-JP / Swallow など)がよく挙げられます。日本語の語彙・文体・物語構造への適応度が英語ベースより自然になりやすい、という見方が主流です。ただし私自身が試していないため、本項は「こういう議論がよく見られる」という整理に留まります。日本語特化系(ELYZA-JP / Swallow)と多言語高性能系(Qwen / Gemma / Command-R)の使い分けや量子化と破綻のトレードオフは、深掘りスポークの ローカルLLM 小説の現実 セクション 3 に委ねます。
小説生成で必ず守るべき 3 つの留意点
- 出力内容の責任は完全に利用者にある:ローカル LLM はフィルタを利用者側で外している場合があり、公開・配布・販売する文章の法的・道義的責任は完全に利用者にあります。
- 著作権・公序良俗・プラットフォーム規約への配慮:公開先(pixiv / 小説投稿サイト / Kindle / Note 等)の規約に従い、実在人物のモデル化・二次創作・暴力/性的表現を扱う必要があります。
- モデルライセンス(商用利用条項):商用販売ではベースモデルのライセンス条項に従い、生成物の権利関係も確認が必要です。
「絶対安全に小説生成ができる」「絶対自由に何でも書ける」とは申し上げません。法的責任は完全に利用者の側にあり、最終判断は法務・弁護士の方へご相談ください。
誰が入れる価値があるか|判断基準・外に出せないデータ・オフライン要件・入れなくていい人

📖 この章で使う用語
- ターミナル:パソコンに文字でコマンドを打って指示を出す画面。営業時代の私は「真っ黒な怖い画面」だと思っていました。
ここまで読んで「で、自分は入れるべきなのか?」が気になっている方へ。職種を 5 つ並べる前に、判断基準を 1 つだけお伝えします。ローカル LLM が効くかどうかは、職種ではなく「外に出せないデータを日常的に触っているか」と「学習目的で中身を知りたいか」の 2 点でほぼ決まります。
私が実際にローカル LLM を入れた理由(学習目的)
私がローカル LLM を入れた一番の理由は、業務効率化ではなく 学習目的 でした。業務ではクラウド API を毎日叩いていますが、API 越しだと「モデルが何 GB で、量子化で何 GB に縮み、推論に何秒かかり、RAM をどれだけ食うか」が一切見えません。Ollama で Llama 3 8B を動かして初めて、毎日 API で呼んでいる相手の物理的な重さが手元で見えるようになりました。これから生成AIエンジニアを目指す未経験の方には、この「中身が見える」体験をいちばん強くおすすめします(未経験からの転職は 未経験エンジニア 転職)。
「外に出せないデータ」を日常的に触る実務の方
もう 1 つの軸が機密性です。顧客リスト・人事評価・契約書ドラフト・社内コードなど、社内規定やフリーランス契約で「外部 AI への入力が禁止されている」データ を日常的に触る方は最大の受益者です。入力も出力もすべて PC で完結し、ネットには 1 バイトも流れないので、「外に出してはいけないデータ」の AI 処理が初めて成立します。
具体的には営業職の受注メモ整形、事務職の個人情報を含む議事録整形、個人事業主の取引先メモ整理、副業ライターの原稿下書き——いずれも「外部 AI 禁止」の壁にぶつかりやすい場面です。これは私の本番運用領域ではなく判断基準の当てはめで、共通する最初の壁は (1) Mac の RAM 容量(16 GB 以上)、(2) ターミナルでの最初のコマンド入力、(3) 社内 IT 部門との合意の 3 点です。
オフライン要件のある方と、逆に「入れなくていい」方
飛行機内・出張先の不安定 WiFi・社内 VPN 縛りで外部サービスが使えない環境も出番です。私も機内モードの MacBook Pro で Ollama + Llama 3 を動かした経験があります。
逆に、外に出して問題ないデータしか触らず、常時ネットがあり、学習目的もない方 は、無理に入れる必要はありません。クラウド API(Claude 使い方 / ChatGPT 始め方)に集中したほうが性能も運用負担も有利です。上の 3 つのどれかに当てはまるかで判断するのが現実的です。
失敗パターン 5 個——個人検証で見つかった落とし穴
📖 この章で使う用語
- 量子化ロス(Quantization Loss):量子化により精度が下がる現象。
個人検証で見つかった失敗パターンと、よく言われる落とし穴を 5 個整理します。
- クラウド API と同じ精度を期待してしまう:いちばん多い落とし穴です。GPT-5 や Claude Opus と同じ感覚で Llama 3 8B に複雑な依頼をすると品質に大きな差を感じます。「フロンティアモデルの代替」ではなく「用途を絞った相棒」と捉え、簡単な整形・要約・読み解きから始めるのが現実的です。
- 量子化選定の誤り:(a) 4-bit で精度が落ちすぎる、(b) 8-bit で RAM 不足になり OS が固まる——のどちらかに陥ります。まず Q4_K_M から触り、品質に不満なら Q5_K_M / Q8_0 に上げる順序が現実的です。
- モデルライセンス未確認で商用利用:Llama / Mistral / Gemma / Qwen / DeepSeek / Phi のいずれもライセンスがモデルごとに異なります。商用利用前に必ず公式を確認し、社内法務・コンプライアンス部門に相談してください。
- 日本語性能を英語モデルでそのまま期待する:Llama 3 8B(英語ベース)に日本語応答を期待すると文法の乱れが目立つことがあります。日本語処理が主体なら ELYZA-JP / Swallow / Qwen / Gemma など日本語学習に重きを置いた系統を選び、最新リリースは Hugging Face でご確認ください。
- 業務本番運用に飛びついてしまう:個人検証 → 部分業務(PoC)→ 業務本番運用の 3 段階を経るのが現実的です。性能・運用負担・モデル更新・ライセンスの 4 つの壁を事前検証せず飛びつくと、後から大きく修正することになりかねません(移行判断は次の業務常用に踏み出すときの注意)。
業務常用に踏み出すときの注意——コスト / 性能 / 運用負担 → API への送り
📖 この章で使う用語
- PoC(Proof of Concept:概念実証):本番導入前の小規模試行。「実証実験」のニュアンス。
- エンタープライズ(enterprise):大企業・組織向け。IAM 連携 / VPC 内通信 / 監査ログなどの要件を含む。
ローカル LLM を業務常用に乗せようと検討している方向けに、3 つの壁と現実的な使い分けを整理します。
業務本番運用の 3 つの壁
壁 ①:性能の壁:フロンティアモデルとローカル OSS LLM の最高峰には、まだ性能差があります(デメリット①性能差 参照)。特定タスクで実用十分でも、汎用業務本番運用としてはクラウド API が現実解です。
壁 ②:運用負担:モデル更新・GPU メンテナンス・スケーリングを自社で運用する負担は想像以上に重い領域です。クラウド AI は運営会社が自動更新しますが、ローカルは社内で運用人員を抱える必要があり、中小規模組織では捻出が難しいケースが多いと言われています。
壁 ③:モデルライセンスとコンプライアンス:商用利用条件はモデルごとに異なり、社内法務・コンプライアンス部門との合意形成が必要です。特にエンタープライズ要件(IAM 連携 / VPC 内通信 / 監査ログ / SOC 2 / ISO 27001 等)が絡むと、自前運用のコストが急上昇します。
現実的な使い分けの提案
業務本番運用のメイン:クラウド API が現実解
- Claude 使い方:Anthropic 直 API を業務本番で運用
- ChatGPT 始め方:OpenAI API も並行運用
- AWS Bedrock:エンタープライズ要件(IAM / VPC / 監査ログ)があるとき
- Claude Opus:深掘り推論や 1M context が必要なとき
- Claude Opus と Sonnet の違い:3 モデルの使い分け俯瞰
特定用途でローカル LLM を組み合わせる:
- 機密情報を外に出せない処理(社内コード整形、顧客リスト整形、人事評価下書き等)
- オフライン環境(飛行機内、出張先、社内 VPN 縛り)
- コスト最適化(大量バッチ処理のうち、機密性低いものをローカルに逃がす)
- 個人検証・学習目的(生成AIエンジニアを目指す方の理解深化)
最終判断は社内情シス・法務・コンプラ部門へ
ローカル LLM の業務本番運用、または部分業務利用を始める前に、必ず社内の情シス・法務・コンプライアンス部門に相談してください。モデルライセンス・データ取り扱い・運用責任の整理は本記事 1 本では網羅しきれず、組織と用途で個別判断が必要です。本セクションは公式情報とクラウド API 側での業務本番運用の経験をもとにした紹介で、最終判断は専門部門と、必要に応じて弁護士の方へご相談ください。
よくある質問(FAQ)
Q1: ローカル LLM だけで業務を回せますか?
A. 「絶対回せる」とは申し上げません。私の業務感覚では、ローカル LLM は 個人検証 → 部分用途で組み合わせる のが現実的で、業務本番のメインは Claude / ChatGPT / Gemini API、エンタープライズ要件があれば AWS Bedrock 経由が筋という整理です。性能・運用負担・モデルライセンスの 3 つの壁が高く、特定用途(社内コードの整形 / 機密データの下処理 / 完全オフライン環境)で組み合わせるのが、2026 年 5 月時点の現実的な姿です。詳細は 業務常用の注意をご参照ください。
Q2: Mac で LLM を動かすには、どのスペックが必要ですか?
A. 「絶対このスペック」とは申し上げません(モデルサイズと用途で振れます)。私の個人検証の感触では、Apple Silicon Mac(M1 以降)+ 16 GB RAM で 7B クラスの量子化版モデル(Q4_K_M)が動く、32 GB RAM で 13B クラスが快適、64 GB RAM で 70B クラスの量子化版が動く——というのが目安です。Windows + NVIDIA GPU の場合は VRAM 12 GB / 24 GB クラスが目安と言われていますが、私自身は Mac での検証のみです。詳細は ハードウェア要件をご参照ください。
Q3: 日本語に強いローカル LLM はどれですか?
A. 「絶対これが一番」とは申し上げません。2026 年 5 月時点で一般的に、(1) Llama-3-ELYZA-JP(ELYZA 社が日本語追加学習)、(2) Swallow(東京工業大学等の継続学習)、(3) Qwen(Alibaba 開発、多言語対応に強み)、(4) Gemma(Google 開発、日本語対応)が代表的に挙げられる系統です。私自身の業務日本語処理は Claude / ChatGPT / Gemini API が主軸で、ローカル日本語モデルは個人検証も限定的なため、本記事は公式情報や評判をもとに紹介する立ち位置です。詳細は 日本語対応モデルをご参照ください。
Q4: ローカル LLM で小説生成はできますか?
A. 「絶対安全にできる」とは申し上げません。設計上、クラウド AI(ChatGPT / Claude / Gemini)が拒否しがちな表現でも、ローカル LLM は自分の責任で自由度の高い出力が可能と言われています。ただし、(1) 出力内容の責任は完全に利用者にある、(2) 著作権・公序良俗・プラットフォーム規約への配慮、(3) モデルライセンス(商用利用条項)の 3 つは絶対に外せません。私自身は、自分の企画の第1話をローカル LLM で生成する検証は行いましたが、長編の作り込みまではしていないため、本記事は公式情報や評判もあわせて扱います。最終判断は法務・弁護士の方へご相談ください。詳細は 小説・創作系のユースケースをご参照ください。
Q5: ローカル LLM を始めるなら、最初の一歩は何ですか?
A. 私の個人検証視点での目安は、Mac M シリーズ(16 GB RAM 以上)+ Ollama + Llama 3 8B / Gemma 7B(量子化版) からの開始です。brew install ollama → ollama pull llama3 → ollama run llama3 の 3 行で動きます。業務本番運用の推奨ではなく、ローカル LLM の感触を掴むための最小動線 として、まず触ってみるのがおすすめです。詳細は 5 分で動かす最小手順をご参照ください。
Q6: ローカル LLM で文章校正はできますか?
A. できます。私の個人検証の感触では、誤字脱字チェック・冗長表現の言い換え・トーン調整 といった文章校正は、ローカル LLM(Llama 3 8B / Gemma 7B / 日本語なら ELYZA-JP)が比較的得意な用途です。社外に出せない契約書ドラフト・人事文書・顧客メールなど、機密性の高い文章をクラウドに貼らずに校正できる のが最大の利点です。コツは、誤字脱字・冗長表現だけ直し、意味と語順は変えない と 直す範囲と触らない範囲を明示する こと——指示がゆるいとローカル LLM は校正を超えて勝手にリライトしがちです。ただし「絶対クラウド AI 並み」とは申し上げません——込み入った文脈理解や長文の一貫性ではクラウド API(Claude / ChatGPT / Gemini)に分があるため、機密文書の一次校正はローカル、最終仕上げは用途に応じて という使い分けが私の業務感覚に近い整理です。プロンプトの型と量子化のつまずきは 用途別おすすめで詳述しています。
筆者について:営業職 7 年から SES・自社開発を経て生成AIエンジニアになった aikun が、MacBook Pro で Ollama を実際に動かした個人検証と、業務でクラウド API(Anthropic / OpenAI / Google)を毎日叩いている手触りをもとに書いています。ローカル LLM の業務本番運用経験はなく、どこまでが自分で触った範囲でどこからが公式情報や評判をもとにした範囲かは、本文で都度明示しています。
出典
- Ollama 公式ドキュメント(取得:2026-05-20)
- Llama 公式(Meta)(取得:2026-05-20)
- Mistral AI 公式(取得:2026-05-20)
- Google Gemma 公式(取得:2026-05-20)
- Qwen 公式(Alibaba)(取得:2026-05-20)
- DeepSeek 公式(取得:2026-05-20)
- Microsoft Phi 公式(取得:2026-05-20)
- Hugging Face Open LLM Leaderboard(取得:2026-05-20)
- LMSYS Chatbot Arena(取得:2026-05-20)
- Apple Silicon 公式情報(取得:2026-05-20)
- LM Studio 公式(取得:2026-05-20)
- llama.cpp GitHub リポジトリ(取得:2026-05-20)
訂正・最新情報のご指摘について:本記事の誤り・最新情報のご指摘は send@bon-bon-tools.com までお知らせください。ローカル LLM はモデル更新サイクルが非常に早く、リリース動向・ライセンス条項は数か月で変わる領域です。各モデル公式と Hugging Face で最新状況を必ず併せてご確認ください。
関連記事
- 日本語 ローカルLLM おすすめ — 本記事の深掘りスポーク。日本語が動くモデルの用途別の選び方・ELYZA/Swallow/Qwen の整理・Mac の最小構成に絞って解説
- LM Studio 使い方——ターミナル不要の GUI でローカル LLM を入れる→モデル管理→OpenAI 互換 API まで、Ollama との使い分けも整理
- ローカルLLM 文章校正の現実 — 本記事の深掘りスポーク。社外秘を外に出さず手元で直す校正用途に絞って、プロンプトの型・精度の限界・クラウドとの使い分けを整理
- Ollama 使い方 — 本記事の深掘りスポーク。入れる→動かす→管理→API組み込みを操作に絞って通しで解説
- ローカルLLM 小説の現実 — 本記事の深掘りスポーク。向くモデル・プロンプト設計・長文の一貫性の壁・著作権まで整理
- ローカルLLM コーディングは実用か — 本記事の深掘りスポーク。向くコード特化モデル・VSCode(Continue)連携・エージェント的な使い方・クラウドとの使い分けに絞って整理
- AI 小説の書き方 — クラウド/小説特化/ローカルの3系統の選び方とプロンプトの型から入りたい人向けの上流ハブ
- LLM とは — LLM 概念ハブ(クラウド主軸)、本記事の親
- AI コードレビュー — セクション 7 でローカル LLM を Code Llama / DeepSeek Coder 中心に既述、本記事への送り元
- AIエージェント 作り方 — 補足ルートとしてローカル LLM 構築を扱う
- RAG とは — RAG 概念ハブ、ローカル LLM + ベクトル DB 構成の概念
- AI コーディング — AI コーディング親ハブ(補完 / 対話 / エージェント 3 レイヤー俯瞰)
- Style-Bert-VITS2 使い方 — 文章だけでなく「声」を手元の PC で作る。日本語音声合成 OSS のインストールと AivisSpeech との違い
- ローカルLLM 画像生成(Ollama で足りる範囲と ComfyUI が要る境界線) — 同じ Mac で「画像」も。Ollama の macOS 対応でどこまでできるようになったか、その先の線引き
- Macでローカル画像生成は実用か(ComfyUI×FLUX) — 同じ Mac で「画像」も回せる。LLM(Ollama)とは別系統の ComfyUI×FLUX を M1 Max で実測した実用ライン
- Macでローカル動画生成は実用か(Wan2.2 実測) — 同じ Mac で「動画」も。Wan2.2 を実機で 2秒9分・フル HD は 25分/秒と実測し、量産できる現実ラインを切り分け
- AWS Bedrock — エンタープライズ AI 基盤クラウド経路
- Claude Sonnet 4.6 — クラウド側主力モデルの最新
- Claude 使い方 — 業務本番運用クラウド API
- ChatGPT 始め方 — 業務本番運用クラウド API
- AI 業務効率化 ツール — 業務効率化ツール俯瞰
- AIエージェント とは — AIエージェント概念ハブ
- Claude Opus — フロンティアモデル比較
- Claude Opus と Sonnet の違い — モデル使い分け俯瞰
- Claude 料金プラン — クラウド API 料金比較
- Claude Code 使い方 — CLI コーディングエージェント
- Claude Code 始め方 — Claude Code 初回 30 分
- Cursor 使い方 — IDE 統合型コーディングエージェント
- Claude Cowork 使い方 — デスクトップエージェント
- Claude Code Action — GitHub Actions 統合
- Dify 使い方 — ノーコード AI エージェント基盤
- AI 業務効率化 事例 — 5 領域×5 職種マトリクス
- AI 議事録 おすすめ — 議事録 AI 整理
- AI 翻訳 おすすめ — 翻訳 AI 整理
- AI 画像生成 無料 — UI ベース無料 6 ツール
- AI 画像生成 プロンプト — 4 要素モデル
- AI 動画生成 おすすめ — 動画 AI 整理
- Claude Skills とは何か——SKILL.md / 自作 3 系統 / Slash commands・MCP・Tools との違いを整理
- Azure OpenAI Service とは何か——GPT/Codex モデル一覧・料金・直 API/AWS Bedrock 3 経路使い分け・「Azure に Claude はない」誤解まで整理
- AIエージェント × MCP——標準仕様の手と目を増やす設計(自作 MCP サーバー本番運用者が整理)
- Claude Skills を自作する——SKILL.md の書き方から業務 3 系統・チーム配布まで「作る側」を実演
- Vibe coding とは——感覚で AI に書かせ、人間はレビューと方向づけに回る新スタイルを業務実践視点で整理
- Codex CLI とは——OpenAI 系の Claude Code 相当を、両方触った現役の生成AIエンジニアが比較しながら整理しました
- Vertex AI とは——Google Cloud の AI 基盤。Gemini と Claude on Vertex の二本柱・料金・3 基盤比較を業務試用視点で整理
- MCP サーバー 作り方——Python/TypeScript SDK で自作し本番運用まで「作る側」の完全マニュアル
- Gemini CLI 使い方——Google のターミナル型 AI コーディングを 3 ツール比較で整理
- Gemini API 使い方——コードから Gemini を呼ぶ最小サンプルを Python・GAS で
- Claude Agent SDK とは——Claude Code の中身(自律エージェントの動き)を Python/TS で自分のアプリに組み込む SDK を業務利用視点で整理