ChatGPT や Claude で小説を書こうとして、「お答えできません」と拒否された経験はありませんか。暴力描写やセンシティブな文学表現を含む創作で、クラウド AI の安全装置に何度もはじかれる——これは創作者の方からよく聞く悩みです。親キーワード「LLM ローカル」のサジェスト(2026 年 5 月時点)でも「小説」は上位に入る関心領域でした。言い換えれば「小説生成AI を、クラウドではなくローカル(ローカルAI)で動かしたい」という関心です。
結論から言うと、ローカル LLM は「クラウド AI が拒否しがちな創作でも、自分の責任で自由度高く書ける選択肢」になり得ますが、性能・長文の一貫性・自己責任という 3 つの現実とセット——というのが筋です。私は営業出身の現役生成AIエンジニアで、業務ではクラウド API を毎日叩く一方、ローカル LLM は Mac で Ollama を触ってきました。2026 年 7 月には、自分の進行中の長編企画の第1話を、ローカル LLM で実際に生成する検証も行いました(全4シーン・約2,500字)。本記事では、なぜローカルか・向くモデル・プロンプト設計・著作権と規約の留意点まで、その経験と公式情報を交えて誠実にまとめます。
まず自分の Mac で動かす感触だけ掴みたい方は、親記事 LLM ローカル のセクション 9「5 分で動かす最小手順」が近道です。本記事はそのうえで「小説に使えるのか」を掘り下げます。
結論|ローカル LLM で小説は書ける、ただし「性能・一貫性・自己責任」とセット

📖 この章で使う用語
- ローカル LLM:自分の PC や手元のサーバで動かす LLM(大規模言語モデル)の総称。「クラウド AI = レンタル車、ローカル LLM = 自家用車」のイメージ。詳しくは LLM ローカル で扱っています。
- クラウド AI:ChatGPT / Claude / Gemini のように、運営会社のサーバで動き、インターネット越しに使う AI。
ローカル LLM で小説は 「書けるが、性能・一貫性・自己責任とセット」——これが一行マップです。3 行で覚えるなら、次の住み分け。
- ローカル LLM = クラウド AI が拒否しがちな表現でも自由度が高く、未公開プロットを外部に出さずに済む(自家用車のように、自分の手元で完結する選択肢)
- クラウド AI(API) = センシティブな題材は拒否されやすい一方、長文の一貫性・推敲の質・速度に強い(レンタル車のように、フル装備で借りて使う選択肢)
- 使い分け = 拒否されやすい題材の下書きや実験はローカル、仕上げは用途で——と組み合わせるのが現実解
新しいローカル LLM のモデルやツールが次々に出てきても、まず「これは自由度を取りに行く場面か、品質を取りに行く場面か」を確かめれば、置き場所に迷わなくなります。
本記事の方針だけ先に。「無修正で何でも書ける」式の手順指南は扱いません。主軸はプロット出し・キャラ設定・推敲・文体調整といった正当な創作支援です。自由度が高いほど、出力責任・著作権・規約・モデルライセンスという現実がついて回るからです(著作権・規約)。
本記事で扱う実測範囲は、自分の企画の第1話をローカルLLMに書かせたところまでです。長編の完結や投稿サイト運用は経験として語らず、モデル名・ライセンスの最新情報は各公式へ委ねます。環境構築の詳細は親記事 LLM ローカル にまとめました。
なぜ小説生成でローカル LLM が選ばれるのか——「拒否」とプライバシーの 2 軸
📖 この章で使う用語
- コンテンツモデレーション(content moderation):AI の出力が不適切な内容を含まないかをチェックする機能。クラウド AI に組み込まれている。テレビ局の「これは放送できる表現か」を確認する作業に近いイメージ。
- 拒否回答(refusal):AI が「お答えできません」と返す挙動。クラウド AI の安全装置の 1 つ。
ここでは、創作者がローカル LLM を選ぶ動機を整理します。動機は大きく「①センシティブな文学表現の自由度」「②未公開プロットを外部に出さないプライバシー」「③オフライン・無料」の 3 つに集約できます。
クラウド AI が創作で拒否を返す理由(content moderation / refusal)
ChatGPT や Claude で創作をしていて、暴力・性・差別・自傷といったテーマに触れた瞬間に「お答えできません」と返ってきた——という経験は、創作者の方からよく聞きます。これは、クラウド AI 提供事業者が コンテンツモデレーション(出力内容をチェックする機能) を組み込んでいるためです。
これは各社の嫌がらせではありません。不特定多数が使うサービスゆえ、提供事業者には利用規約・法令・プラットフォーム責任があり、テレビ局が「放送できる表現か」を確認するのと同じく自社の責任で安全装置を設けています。文学的に正当な暴力描写でも、文脈を読み切れず過剰に拒否される(過検出)ことがありますが、それも安全側に倒した結果です。
ローカル LLM の OSS モデル(モデル重みが公開されているモデル)の多くは、こうしたクラウド側のモデレーションを経由しません。そのため、クラウド AI が拒否しがちなセンシティブな文学表現でも、自分の責任で出力できる自由度がある——と言われています。ただし、これは「何を書いても許される」という意味ではありません。後述の通り、出力責任・著作権・規約はすべて利用者に残ります(著作権・規約)。
プライバシー——未公開原稿・プロットを外部に送らない価値
もう 1 つの動機がプライバシーです。クラウド AI にプロットや原稿を入力すると、文章は運営会社のサーバを経由します。多くの事業者は「API 入力はモデル学習に使わない」としていますが、それでも「未公開の自作プロットを外部に送ること自体に抵抗がある」という創作者は少なくありません。
連載前の構想、応募予定の新人賞作品、未発表の世界観設定——こうした「世に出る前の原稿」を自分の PC の中だけで処理でき、ネットには 1 バイトも流れないのがローカル LLM の価値です。業務で機密コードや顧客情報を扱うときの「外に出したくないデータは手元で」という判断軸と、根は同じです。
ただし自由度の代償として、(1) 性能差、(2) 長文の一貫性、(3) 自己責任という 3 つの現実がついて回ります。特に (3)「自由に書ける=何を書いても許される」ではない点は重要で、著作権・規約 で本記事の中核として扱います。
選んで動かして書かせる|向くモデル・Mac の最小環境・プロンプトの型
📖 この章で使う用語
- パラメータ(規模):モデルの「脳のサイズ」の目安。7B(70 億)/ 27B / 70B のように表記し、大きいほど賢くなりやすいが、重くて高スペックを要求する。
- 量子化(quantization):モデルを軽くして普通の PC でも動くように圧縮する技術。写真を JPEG で軽くするイメージ。詳しくは LLM ローカル で扱っています。
- ファインチューン(fine-tuning):既存モデルに追加学習させて、用途(ここでは創作)に寄せること。
ここから、日本語小説の文脈でよく挙がるモデルの系統を、「日本語の自然さ」「パラメータ規模」「量子化で手元の PC でも動くか」の 3 軸で整理します(使い込みの品質評価は検証範囲外で、公開実験や創作コミュニティの知見をもとにした整理です)。
日本語特化系(ELYZA-JP / Swallow)——文体・語彙の自然さ
英語ベースのモデルに日本語の小説を書かせると、文法の乱れや不自然な言い回しが出やすい傾向があります。そこで、日本語データで追加学習させた 日本語特化系 が、文体・語彙の自然さで言及されます。
- Llama-3-ELYZA-JP:日本企業の ELYZA 社が Llama 3 をベースに日本語追加学習させた OSS LLM。日本語タスクでの評価が高いとよく言われる系統です(最新リリースは Hugging Face の elyza アカウントでご確認ください)
- Swallow:東京工業大学(現・東京科学大学)等の共同研究で、Llama などをベースに日本語データで継続学習させた系列
日本語の地の文・会話文の自然さを重視するなら、まずこの系統が候補に挙がります。商用利用にはベースモデル(Llama 等)のライセンス条項が継承される点に注意が必要で、詳しくは 著作権・規約 で扱います。
多言語高性能系(Qwen / Gemma / Command-R)——理解力・要約力
次に、日本語特化ではないものの多言語性能が高く、日本語小説の文脈でも言及される系統です。
- Qwen(Alibaba):多言語対応に強み。日本語タスクの性能も高く評価されることがあり、0.5B から 72B クラスまで幅広いサイズ展開があります
- Gemma(Google):Gemini 系の研究を OSS 化した位置づけ。日本語応答の品質も評価される系統の 1 つ
- Command-R 系(Cohere):長文の理解力・要約力で言及される系統。設定の多い長編の文脈把握で名前が挙がることがあります
これらは「理解力・要約力」を活かして、長い設定や前章のあらすじを踏まえて書かせる用途で言及されます。日本語の地の文の自然さでは日本語特化系に分があることもあるため、用途で使い分けるのが現実的です。
創作向けファインチューン系(評価は各自で確認を)
汎用モデルをベースに 創作(ロールプレイ・小説生成)に寄せてファインチューンした派生モデル が話題になることがあります。magnum 系などの名前が、創作コミュニティ(Hugging Face / Reddit の r/LocalLLaMA 等)で観測されます。
ただし派生モデルの品質・センシティブ表現への振る舞い・ライセンスは私の検証外で断定できません。利用前に、各モデルカードのライセンスと創作コミュニティの最新評価を必ずご自身で確認してください。
モデル規模と量子化のトレードオフ(小さいと速いが破綻しやすい)
最後に、モデル選びで効いてくる「規模」と「量子化」のトレードオフです。ここは私が Ollama を個人検証した範囲から、体感として補足できる部分です。
一般に、パラメータ規模が大きいモデルほど、長い文脈を踏まえた一貫性のある文章が書きやすい傾向があります。一方で、規模が大きいほど高スペックの PC を要求します。そこで量子化(モデルを圧縮する技術)でサイズを落とすのですが、圧縮を強くかけすぎると、日本語の崩れや破綻が出やすくなる印象です。
中規模(20〜30B の量子化版、24 GB VRAM 級または 32〜64 GB RAM の Mac)で、章分割前提に数万字の長編を書かせた報告も見かけます。私の体感では、まず手元で動くサイズの量子化版を試し、破綻が目立てば量子化を緩める順序が現実的でした(用途と PC スペックで振れます)。
自分の Mac で小説用に動かす最小環境——Ollama / LM Studio(環境構築は自分で触った範囲)
📖 この章で使う用語
- Ollama(オラマ):コマンドでローカル LLM を動かす定番ツール。CLI(文字でコマンドを打つ画面)ベース。
- LM Studio:画面(GUI)でローカル LLM を動かせるツール。長文を打ち込む創作に向きやすい。
ここは 私が実際に Mac(MacBook Pro)で Ollama を動かした範囲 としてお話しできる章です。「小説用に何を選び、どう試すか」に絞ります(インストール手順の詳細は親記事 LLM ローカル のセクション 9 に、小説用に Mac を選ぶなら ローカルLLM 向け Mac の選び方 に送ります)。
Ollama vs LM Studio——長文創作なら GUI が快適(体感)
ローカル LLM を動かす入り口として、創作の文脈では Ollama と LM Studio の 2 つが現実的な選択肢です。
- Ollama:CLI(真っ黒な画面に文字を打つ)ベース。
ollama pullでモデルを入れ、ollama runで対話できます。スクリプトから自動で呼び出したい、RAG やエージェントに組み込みたい、という場合に向きます - LM Studio:GUI(画面操作)ベース。Hugging Face のモデルを画面から検索・ダウンロードでき、チャット画面も内蔵されています。長い設定文やプロットを貼り付けて、画面を見ながら書き進める創作スタイルには、こちらが快適に感じやすいと思います
私の検証は Ollama 中心ですが、長い創作プロンプトを推敲していく用途なら、履歴を見渡せる GUI(LM Studio)のほうが向きやすい体感です。営業時代の私も CLI は「怖い画面」だったので、抵抗があれば LM Studio から入るのも手です。
LM Studio で小説を書き始める流れはシンプルで、①アプリを入れる → ②モデル検索窓で日本語対応モデル(本記事のおすすめモデル参照)を探して読み込む → ③内蔵チャットに設定・プロットを貼って書かせる、の 3 手です。ターミナルは一度も開きません。インストールとモデル管理の詳細・読み込みエラーの対処は LM Studio 使い方 に分けて整理しています(プロンプトの型と長編の一貫性の壁は、このあとの章がそのまま使えます)。
まず日本語が動くか、数百字で動作確認する
最初の一歩は、日本語対応モデルを 1 つ入れて短い場面を数百字だけ書かせる動作確認です。Ollama なら量子化版を ollama pull で落として情景描写を頼んでみる。見るのは「日本語が自然に出るか」「実用速度で動くか」の環境確認で、向き不向きの品質評価ではありません。
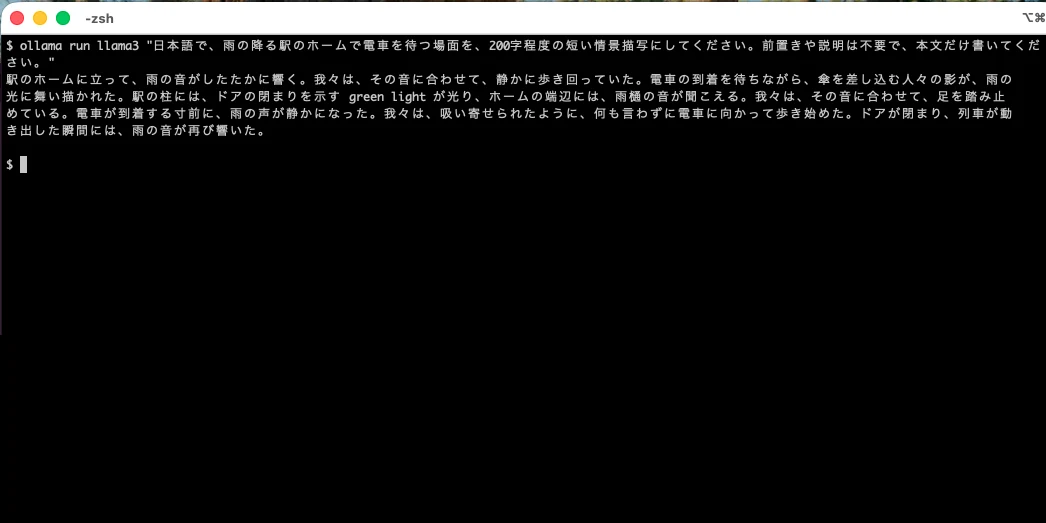
※ 私の Mac で Ollama(llama3)を動かした画面。日本語が動く動作確認で、品質評価ではありません。llama3 は英語ベースのため英単語(“green light”)が混じります——自然さを求めるなら 向くモデル の日本語特化系(ELYZA-JP / Swallow)を。
必要な PC スペックは扱うモデル規模に直結します。Apple Silicon Mac の目安は、16 GB RAM で 7B クラスの量子化版、32 GB で 13B クラス、64 GB で 70B クラス。長編の一貫性で中〜大規模を使うなら、それなりの RAM が要ります。詳しい選び方(VRAM・統合メモリ・量子化)は親記事 LLM ローカル のセクション 5 へ。
「Ollama で小説」を試す最小コマンド手順
「ollama 小説」で来られた方向けに、Ollama で創作を試す最小の流れだけ置いておきます(動作確認まで。品質評価ではありません)。
# 1) 日本語が動くモデルを量子化版で入れる
# (モデルの顔ぶれはセクション 3 を参照。最新の入手可否・ライセンスは各モデル公式で要確認)
ollama pull <日本語対応モデル>
# 2) 対話モードで起動して、短い場面を書かせてみる(動作確認)
ollama run <日本語対応モデル>
# 3) プロンプト例(健全な創作の動作確認):
# 以下の設定で、200 字程度の情景描写を書いてください。
# 設定:夜明け前の港町/主人公は漁に出る前の老人/視点:三人称Ollama の詳しい使い方(オプション・モデル管理・REST API/Python・GUI 化)は兄弟記事 Ollama 使い方 に。創作プロンプトは プロンプトの型、長文の一貫性は 長文の一貫性、著作権・規約は 著作権・規約 で扱います。出力の責任と権利関係は最後まで利用者側に残ります。
小説を書かせるプロンプト設計の型——設定・文体・視点を渡す 4 ブロック
📖 この章で使う用語
- プロンプト:AI への指示文。営業時代の「話す前に整える台本」のイメージ。
- システムプロンプト:AI 全体の前提・役割を最初に固定する指示。「この AI は時代小説の語り手」と最初に役を与えるイメージ。
小説を一場面だけ試すなら、この無料記事の4ブロックで十分です。第1話を通すと「設定をいつ渡し直すか」「失敗した出力をどう直すか」が次の壁になります。そこまで一度に追いたい方には、実際の初稿・失敗テイク・リテイクとプロンプト30本をまとめた¥980のガイドがあり、環境構築の章までは note で無料試し読みできます(価格・内容の最新情報は note でご確認ください)。
次の 4 ブロックに分けて渡すと、AI が「何を・誰を・どう・どこまで」書けばいいか掴みやすくなります。
- ①世界観・設定:時代・場所・ジャンル・前提。「現代日本の地方都市」など
- ②キャラクター・関係性:名前・性格・口調・関係。「主人公は寡黙な高校教師、相棒は饒舌な後輩」など
- ③文体・視点・時制:一人称/三人称・語り手・敬体/常体・時制。「三人称・主人公視点・常体・過去形」など
- ④出力制約:「この場面を 800 字で」「会話文中心」「起承転結の承を」など
さらに、長く書かせると文体や視点がぶれがちなので、システムプロンプト(AI の役割を最初に固定する指示)で語り手を固定します。例:「あなたは三人称・常体・過去形の語り手。説明しすぎず情景で語ってください」。役を最初に与えると、章をまたいでも文体がぶれにくくなります。
4 ブロックを組み込んだ短い雛形です(健全な題材で例示。構造は同じ発想で応用できます)。
# システムプロンプト(語り手の固定)
あなたは三人称・主人公視点の語り手です。常体・過去形で、
情景描写を中心に、説明的になりすぎないトーンで書いてください。
# ユーザープロンプト(4 ブロック)
【世界観・設定】現代日本の海辺の町。季節は晩秋。
【キャラクター】主人公は古書店を継いだ30代の女性。無口だが観察眼が鋭い。
【文体・視点・時制】三人称、主人公視点、常体、過去形。
【出力制約】開店前の店内を描く導入シーンを、600〜800字で。会話は入れない。雛形は出発点。出てきた文章を見て制約を足し引きして調整します(プロンプト設計の発想は AI 画像生成 プロンプト でも整理)。
目的別のコピペ雛形 4 種(章立て / キャラ設定 / 推敲 / 文体)
一発で全部書かせるより、目的を 1 つに絞ったほうが中小規模モデルでも安定します。創作でよく使う 4 目的のコピペ雛形です(いずれも健全な題材前提。採否と責任は書き手に=著作権・規約)。
(1) 章立て・プロットを出させる雛形——いきなり本文ではなく、まず骨組みを作らせます。
次の前提で、短編小説の章立て(プロット)だけを作ってください。本文はまだ書かないでください。
【ジャンル】現代ミステリ
【舞台】地方の温泉旅館、二泊三日
【主人公】旅館を継ぐか迷う30代の元会社員
【出力】起承転結の4部構成で、各部を1〜2行のあらすじで。伏線になりそうな要素を1つ含める。(2) キャラクター設定シートを作らせる雛形——人物がぶれる原因は設定の不足です。先に固めます。
次のキャラクターの設定シートを作ってください。
【名前】未定(候補を3つ提案)【年齢・性別】20代女性
【役割】主人公の相棒【性格】饒舌だが芯は冷静
【出力項目】口調の特徴/一人称/よく使う言い回し/弱点/主人公との関係
箇条書きで、各項目1〜2行で簡潔に。(3) 既存の原稿を推敲・リライトさせる雛形——ゼロから書かせるより、手元の文章を直させるほうがローカルでも安定しやすい用途です。
次の文章を推敲してください。意味は変えず、以下の観点で直してください。
【観点】①冗長な表現を削る ②同じ語尾の連続を避ける ③情景が浮かぶ描写に寄せる
【出力】(1)推敲後の文章 (2)直した箇所を3点だけ箇条書きで説明
--- 原稿 ---
(ここに自分の文章を貼る)(4) 文体を指定して書かせる雛形——「誰の文章っぽく」ではなく、特徴を言葉で指定するのが、権利面でも安全な渡し方です。
次の特徴の文体で、指定の場面を書いてください。
【文体の特徴】短い文を重ねる/比喩は控えめ/視点人物の心情は直接書かず行動で示す
【場面】主人公が古い手紙を見つけて読み始める導入、500字程度、三人称・過去形
特定の作家名を模倣するのではなく、上の特徴だけを手がかりにしてください。4 つに共通するのは、目的を 1 つに絞る・出力の形を先に指定する・出てきたものを見て調整する、の 3 点です。モデルや題材で相性は変わるので、手元で試しながら調整してみてください。第1話の冒頭・続きの場面・会話シーン・あらすじ出しまで含めたコピペ雛形10本の完全版は、小説プロンプト実例集 に分けて置きました(長編で毎章貼り直す運用テンプレ付き)。
つまずきと守りごと|長文の一貫性・日本語の癖・著作権と規約
📖 この章で使う用語
- コンテキストウィンドウ(context window):AI が一度に覚えていられる文章量の上限。机に広げられる紙の枚数のイメージ。超えると前の話を忘れる。
- 段階詳細化:あらすじ → 章立て → 各章本文、と段階を踏んで具体化していく書き方。
- RAG(検索拡張生成):過去の章や設定を「検索して AI に渡す」仕組み。詳しくは RAG とは で扱っています。
長編を書かせたときに多くの人がぶつかるのが「一貫性の壁」です。本章はその仕組みと回避策を整理します(長編創作での具体的な回避テクは検証範囲外で、一般に挙げられる方法の整理です)。
なぜ長文で破綻するのか(context window の制約)
ローカル LLM(特に中小規模のモデル)で長編を書くと、設定の食い違い・キャラクターの性格の崩れ・話の迷子が起きやすくなります。主な原因は コンテキストウィンドウ(AI が一度に覚えていられる文章量の上限)です。
机に広げられる紙に上限があるのと同じで、AI も一度に見ていられる量に限りがあります。超えると最初の設定や口調を忘れ、3 章で寡黙だった主人公が 10 章で饒舌になる、といった破綻が起きます。クラウドのフロンティアモデルほどこの上限が大きく、ローカルの中小規模モデルは早く壁にぶつかりやすい、という整理です。
章分割と段階詳細化(プロット → 章立て → 本文)
よく挙げられる回避策の中心が、章分割と段階詳細化です。一発で長編を書かせようとせず、段階を踏んで具体化していきます。
- まず あらすじ(数百字)を作る
- 次に 章立て(各章で何が起きるかの箇条書き)に展開する
- そのうえで 各章の本文を、1 章ずつ生成する
こうすると AI が一度に扱う量が「その 1 章分」に収まり、壁にぶつかりにくくなります。フルコースを一度に作らず工程を分けるのに似ています。
設定シート・あらすじの再注入 / RAG での文脈保持
章分割をしても、各章を書くときに AI は前章の内容を「忘れている」ことがあります。そこで、章を書くたびに 設定シート(人物・世界観のメモ)とあらすじを、毎回プロンプトに添える、という運用がよく取られます。「この章を書く前に、主人公の設定とここまでのあらすじを思い出してください」と、毎回渡し直すイメージです。
さらに進んだ手として、過去章や設定を自動で検索して AI に渡す RAG(検索拡張生成) を組み合わせ、毎回全文を貼り直す手間を減らすアプローチもあります(基礎は RAG とは)。環境構築の難度は上がりますが、長編の一貫性を保つ選択肢として挙げられます。
日本語小説ならではの留意点——文体・固有名詞・ルビ・出力の癖
📖 この章で使う用語
- 組版記号:ルビ・三点リーダ(……)・ダッシュ(——)など、小説の体裁に使う記号。
ここでは、日本語で小説を書かせるときに出やすい癖を整理します(一般に言われる点が中心、品質評価は各自で)。
英語ベースのモデルに日本語小説を書かせると、文法の乱れや不自然な言い回しが出やすい——前述の通り(向くモデル)、日本語特化モデルが有利になりやすいのはこのためです。私が日本語モデルを動作確認した短い範囲でも、英語ベースと日本語追加学習版で地の文の自然さに差を感じる場面はありました。
具体的に、日本語創作で出やすい癖としては、次のようなものがよく挙げられます。
- 漢字・カタカナ・固有名詞の揺れ:同じキャラクター名の表記が途中で変わる、固有名詞の漢字が揺れる
- 組版記号の扱い:ルビ・三点リーダ(……)・ダッシュ(——)といった小説特有の記号が、意図通りに出ないことがある
- 敬体/常体の混在:常体(だ・である)で統一したいのに、途中で敬体(です・ます)が混ざる
下処理は、(1) プロンプトで表記ルール(人名の漢字・記号・文体)を明示する、(2) 生成後に表記揺れを一括で直す前提で運用する、が現実的です。どのモデルがきれいに体裁を出せるかはバージョンで振れるので、評価は各自でご確認ください。
著作権・規約・公序良俗・自己責任——小説生成で外せない 4 点
📖 この章で使う用語
- モデルライセンス:そのモデルを「どう使ってよいか」を定めた利用条件。商用利用の可否はモデルごとに違う。
- 公序良俗:社会一般の常識・道徳。これに反する内容は、ローカルで作れても社会的な責任を問われ得る。
ここは本記事の中核です。ローカル LLM は自由度が高いぶん、利用者が引き受ける責任も大きくなります。「絶対に安全・自由に何でも書ける」わけではありません。以下の 4 点は、創作の自由を否定するためでなく、創作を続けるための土台です。
出力内容の法的・道義的責任は完全に利用者にある
クラウドの安全装置を、ローカルでは利用者が引き受けます。生成物を公開・販売・共有する判断と、その法的・道義的責任は完全に利用者にあります。AI が出力したから免責される、ということはありません。
著作権・公序良俗・投稿先プラットフォーム規約への配慮
公開や投稿を考える場合、次の 3 つへの配慮が外せません。
- 著作権:既存作品の二次創作、実在の人物をモデルにした描写などは、著作権・パブリシティ権・名誉毀損といった論点に触れ得ます
- 公序良俗:ローカルで技術的に生成できることと、社会的に問題ないことは別です
- 投稿先プラットフォーム規約:pixiv・小説投稿サイト・Kindle ダイレクト・パブリッシング(KDP)・note などは、それぞれ独自の規約を持ち、AI 生成物の扱いやセンシティブ表現の基準も異なります
特にプラットフォーム規約は改定されることがあるため、投稿前に最新の規約を必ずご確認ください。「ローカルで作れたから、どこに出しても大丈夫」とは申し上げません。
モデルライセンス(商用販売時の商用利用条項)
小説を商用で販売したい場合に、特に注意が必要なのが モデルライセンス(そのモデルをどう使ってよいかの利用条件)です。OSS LLM だからといって、何でも自由に商用利用できるわけではありません。
2026 年 5 月時点で、Llama は Community License、Mistral は Apache 2.0 と独自の混在、Gemma は Gemma Terms of Use——と条項がモデルごとに違い、生成物の商用可否も左右され得ます。商用販売の前に、(1) モデルのライセンス、(2) 投稿先・販売先の規約を、必ず公式でご確認ください。
「絶対安全・自由」とは申し上げない——最終判断は法務・弁護士へ
本記事は情報の整理であり、法的アドバイスではありません。著作権・パブリシティ権・各プラットフォーム規約・モデルライセンスの解釈は、個別事情で変わり得る専門領域です。商用販売や判断に迷う題材は、社内法務・コンプライアンス、必要に応じて弁護士の方へご相談ください。足元の責任関係を整理しておくことが、結果的に長く書き続けることにつながります。
実践|クラウドとの使い分け・創作ユースケース 5 例・よくある失敗
「クラウドは不自由だからローカルが最高」という単純な話ではありません。長文の一貫性・推敲の質・速度はクラウド API(Claude / ChatGPT / Gemini)に分があるのが、業務で毎日叩いている私の率直な感覚です。コンテキストウィンドウ(覚えていられる量)が大きく、長い物語の文脈を保ちやすいのもクラウド側の強みです。
一方で、ローカル LLM が効く場面もはっきりしています。
- 拒否されやすい題材の下書き:クラウドの安全装置にはじかれやすいセンシティブな題材を、自分の責任で下書きする
- 未公開プロットの非公開処理:世に出る前の構想を、外部に送らずに手元で整理する
- 無料・オフライン:固定費をかけたくない、ネットのない環境で書きたい
プロット出し・推敲・あらすじ要約は、クラウド AI も得意です。同じ構成技法や確認手順を Claude で繰り返したい場合は、Claude Skills を自作して手順を常設する方法へ進めます。
現実解は、未公開プロットを外へ出さず第1話まで試すならローカル、技法の型を Claude に常設するならクラウドという選択です。前者はローカル実測ガイド、後者は末尾の Claude Skills ガイドで分けて選べます。
非エンジニアの創作ユースケース——小説・シナリオ・同人で AI をどう活かすか(5 例)
創作実用の具体像を 5 つ、表で示します(品質評価でなく「どう使えるか」の見取り図。環境構築はいずれも親記事の最小手順で 30 分前後)。
| 誰が | Before → After | 注意点 |
|---|---|---|
| 兼業小説家 | 未公開原稿を外に出せず推敲を自力 → 手元だけで AI 推敲・言い換え | 採否と責任は利用者(著作権・規約) |
| 同人作家 | クラウドが二次創作・センシティブ表現を拒否 → 自分の責任で下書きの壁打ち | 投稿前に原作ガイドライン+投稿先規約を必ず確認(著作権・規約) |
| シナリオ(ゲーム/TRPG) | 分岐セリフを 1 つずつ手書き → 候補を大量生成して選ぶ・直す | 一貫性はプロンプトの型/商用はライセンス確認 |
| 副業ライター | 取材メモから構成案を毎回手作業 → 叩きを自動生成 | 機密はローカルが有利/事実確認は必ず人の手で |
| エンジニア志望 | 何を題材に動かすか不明 → 小説題材でプロンプト設計・長文制御・RAG を学ぶ | 環境構築自体が学習機会 |
営業時代の私だったら、まず「取材メモから構成案」のような、手元で完結して失敗しても外に出ない用途から試したと思います。いきなり完璧を目指さず、小さく動かすのが近道です。
失敗・つまずきパターン 5 個——期待値とのギャップ
最後に、つまずきやすいパターンを 5 つ整理します(量子化・RAM・日本語の動作は私が Ollama を触った体感、小説品質は一般的な知見をもとにした整理です)。
- クラウド並みの一貫性を期待して破綻:長編は章分割が前提、という期待値で臨む(長文の一貫性)。
- 量子化を下げすぎ/RAM 不足:強く圧縮すると日本語が崩れ、大きすぎるモデルは固まる。まず軽く動くサイズから、不満が出たら上げる(目安は Mac の最小環境)。
- 英語モデルで日本語が不自然:日本語特化系や、日本語評価の高いモデルを候補に(日本語の癖)。
- 長編を一発生成して迷子:あらすじ→章立て→各章本文の段階詳細化を前提にするほうが早い(長文の一貫性)。
- ライセンス未確認で商用販売:いちばんリスクが大きい。踏み出す前にライセンスと規約を確認、迷えば法務・弁護士へ(著作権・規約)。
書けた原稿を売る前に|Kindle は「AI で書いたか」を聞いてくる
ここまでで手元にあるのは、外に出さずに最後まで書き切った原稿です。それを電子書籍として出す段になると、モデルのライセンスとは別に、出し先の側のルールがもう 1 つ増えます。AI で書いたことを申告するかどうか、という区分です。
分かれ目は、直した量ではなく「最初の文を誰が書いたか」でした。KDP 公式の原文と、ローカル LLM で書いた場合がどちらに当たるかの当てはめはKindle出版とAIの申告にまとめています。
よくある質問(FAQ)
Q1. ローカル LLM なら、クラウド AI が拒否する小説でも自由に書けますか?
A. 設計上、クラウド AI が拒否しがちな表現でも、自分の責任で自由度の高い出力ができると言われています。ただし「絶対に安全・自由に何でも書ける」とは申し上げません。出力責任は完全に利用者にあり、著作権・公序良俗・投稿先規約・モデルライセンスは外せません。私自身も自分の企画で第1話を生成する検証を行いましたが、出力の責任・権利確認は利用者にあり、最終判断は法務・弁護士の方へ。
Q2. 日本語の小説に向くローカル LLM はどれですか?
A. 「絶対これが一番」とは申し上げません。一般的に、日本語特化系(Llama-3-ELYZA-JP / Swallow)や多言語高性能系(Qwen / Gemma / Command-R)が、日本語小説の文脈でよく挙がります。私自身は小説生成までは試していないので、最新の評価は各モデルカード・創作コミュニティでご確認ください。
Q3. 長編小説を書かせると話が破綻します。どうすればいいですか?
A. コンテキストウィンドウ(一度に覚えていられる量)の制約が主な原因です。回避策としては、あらすじ → 章立て → 各章の段階詳細化、設定シートやあらすじの再注入、RAG での過去章の文脈保持がよく挙げられます。一発生成より章分割が現実的です。
Q4. 小説を商用販売したいのですが、ローカル LLM で作って問題ないですか?
A. モデルライセンスの商用利用条項に従う必要があり、Llama / Mistral / Gemma 等で条項が異なります。生成物の権利関係・投稿先規約・著作権も含めて、必ず公式ドキュメントを確認し、社内法務やコンプライアンス、必要に応じて弁護士の方へご相談ください。「絶対に問題ない」とは申し上げません。
Q5. クラウド AI(ChatGPT / Claude)でも小説は書けますか。わざわざローカルにする必要はありますか?
A. 健全な創作支援(プロット出し・推敲・文体調整・あらすじ要約)はクラウド AI でも十分にできますし、長文の一貫性や推敲の質はクラウド API に分があるのが私の業務感覚です。ローカルが効くのは「拒否されやすい題材の下書き」「未公開プロットの非公開処理」「無料・オフライン」の場面です。詳しくは LLM ローカル もご覧ください。
Q6. LM Studio だけで小説を書けますか?日本語でも大丈夫ですか?
A. 書けます。①アプリを入れる → ②モデル検索窓で日本語対応モデル(おすすめモデル参照)を読み込む → ③内蔵チャットに設定・プロットを貼って書かせる、の 3 手でターミナルは一度も開きません。日本語は選ぶモデル次第で、日本語特化系や多言語高性能系から選べば大丈夫です。長い設定文を貼って推敲するスタイルなら GUI の LM Studio が快適に感じやすい体感です(最小環境の章、導入の詳細は LM Studio 使い方)。
関連記事
- AI 小説の書き方(まず全体像から) — クラウド・小説特化・ローカルの3系統の選び方と、プロンプトの型・著作権・賞の注意を一望できる入り口。本記事はその「ローカルで書く」深掘り
- ローカルLLM 検閲なしとは — クラウドAIに戦闘・恋愛描写を拒否される問題の整理。仕組みと、使う前に知るべき法令・投稿先規約の責任
- LM Studio 使い方——ターミナル不要の GUI でローカル LLM を入れる→モデル管理→OpenAI 互換 API まで、Ollama との使い分けも整理
- LLM ローカルを Mac で5分|Ollama で小説・日本語まで動かす方法
- 日本語 ローカルLLM おすすめ — 兄弟スポーク。日本語が動くモデルの用途別の選び方・ELYZA/Swallow/Qwen・Mac の最小構成
- Ollama 使い方|入れる→動かす→管理→API組み込みを通しで
- ローカルLLM 文章校正の現実|社外秘を出さず手元で直す
- RAG とは何か——営業出身の現役エンジニアが、日常のたとえで丸ごと整理しました
- AI 画像生成 プロンプトの作り方
- Claude Skills を自作する——SKILL.md の書き方から業務 3 系統・チーム配布まで「作る側」を実演
- Vibe coding とは——感覚で AI に書かせ、人間はレビューと方向づけに回る新スタイルを業務実践視点で整理
- Codex CLI とは——OpenAI 系の Claude Code 相当を、両方触った現役の生成AIエンジニアが比較しながら整理しました
- Vertex AI とは——Google Cloud の AI 基盤。Gemini と Claude on Vertex の二本柱・料金・3 基盤比較を業務試用視点で整理
- Macでローカル画像生成は実用か(ComfyUI×FLUX) — 小説と同じ Mac で「画像」も。挿絵やイメージづくりに、M1 Max で実測した実用ライン
- Macでローカル動画生成は実用か(Wan2.2 実測) — 同じ Mac で「動画」も。Wan2.2 を実機で実測し、量産できる現実ラインを切り分け
- MCP サーバー 作り方——Python/TypeScript SDK で自作し本番運用まで「作る側」の完全マニュアル
- Style-Bert-VITS2 使い方 — 書いた小説を「声」にする。日本語音声合成 OSS のインストールと AivisSpeech との違い
- Gemini CLI 使い方——Google のターミナル型 AI コーディングを 3 ツール比較で整理
- Gemini API 使い方——コードから Gemini を呼ぶ最小サンプルを Python・GAS で
- Claude Agent SDK とは——Claude Code の中身(自律エージェントの動き)を Python/TS で自分のアプリに組み込む SDK を業務利用視点で整理
出典
- Ollama 公式(取得:2026-05-31)
- Hugging Face — ELYZA(取得:2026-05-31)
- Hugging Face — tokyotech-llm(Swallow)(取得:2026-05-31)
- Qwen 公式(取得:2026-05-31)
- Google Gemma(取得:2026-05-31)
- Llama 公式(ライセンス)(取得:2026-05-31)
- Reddit — r/LocalLLaMA(取得:2026-05-31)
- pixiv ヘルプ(規約・ガイドライン)(取得:2026-05-31)
- Amazon Kindle ダイレクト・パブリッシング(取得:2026-05-31)
訂正・最新情報のご指摘について:本記事の誤り・最新情報のご指摘は send@bon-bon-tools.com までお知らせください。ローカル LLM はモデル更新サイクルが非常に早く、モデルの顔ぶれ・ライセンス条項・各プラットフォーム規約は数か月で変わる領域です。各モデル公式・Hugging Face・投稿先の最新情報を必ず併せてご確認ください。