ChatGPT を覚えたと思ったら、次は Copilot、その次は Gemini、Claude——新しい AI ツールが毎週のように出てきて、整理が追いつかないと感じていませんか。実際、ラッコキーワードの実測(2026 年 5 月時点)でも「LLM とは」というキーワード単体で月 3 万人以上が同じ問いに迷っている状態で、私自身も非エンジニア部門からの「結局これ全部、何がどう違うの」という質問に毎週のように答えています。
結論から言うと、LLM は「文章を予測する装置」、ChatGPT・Claude・Gemini はその装置を載せたチャットアプリ、AIエージェント・RAG はその応用——この 3 行の地図さえ掴めば、新しいツールが出てきても置き場所に迷わなくなるのが筋です。本記事では、AI /生成AI/ LLM の入れ子構造から、5 系統の代表 LLM、Copilot との関係、業務での法律的注意点まで、業務で OpenAI / Anthropic / Google の API を叩いている現役の生成AIエンジニア視点で整理します。
LLM の全体像|「文章を予測する装置」と、それを載せたアプリの地図
📖 この章で使う用語
- LLM(Large Language Model:大規模言語モデル):ChatGPT や Claude などの「中身」を動かす、文章を予測する巨大な装置。読み方は「エルエルエム」。
- 生成AI(Generative AI):文章・画像・音声などを「新しく作り出す」AI の総称。AI の大きなカテゴリの 1 つ。
- AI(Artificial Intelligence:人工知能):機械に判断・予測・生成などをさせる技術の総称。LLM・生成AI を含む最も大きい言葉。
- パラメータ:LLM が「言葉と言葉の関係」を数値で覚えている、その数値の数。「司書の頭の中の整理棚の引き出しの数」のイメージ。
LLM は「文章を予測する巨大な装置」で、ChatGPT・Claude・Gemini はその装置を載せたチャットアプリです。エンジンと車体の関係に近く、エンジン単体ではドライブできません。チャット画面・料金プラン・ログインのしくみを周りに付けたものが、ChatGPT・Claude・Gemini です。
3 つの言葉の関係を、入れ子の図で書くと次のようになります。
[ AI(人工知能) ]
└─ [ 生成AI(新しく作り出す AI のカテゴリ) ]
└─ [ LLM(文章を予測する装置) ]
└─ [ ChatGPT / Claude / Gemini など、LLM を載せたアプリ ]「AI」は最も大きい言葉、「生成AI」はその中の 1 カテゴリ、「LLM」はさらにその中で文章を扱う装置の名前、ChatGPT などはその LLM を使えるようにしたアプリ——という階層です。私は本業で Ruby・Python・Scala から OpenAI / Anthropic / Google の API を直接呼び出して LLM を業務プロダクトに組み込んでいますが、読者が日常で触る ChatGPT・Claude.ai・Gemini アプリと、私が API 越しに叩く LLM は、同じエンジンを別の入口から触っているだけです。
頭の整理用に、もう一段シンプルにすると次の 3 行です。サジェストに並ぶ「ai」「chatgpt」「copilot」も、すべて「この 3 行のどこに当てはまる?」の言い換えにすぎません。
- LLM = 文章を予測する装置
- ChatGPT・Claude・Gemini = それを使えるチャットアプリ
- AIエージェント・RAG = それを土台にして組み立てた応用
LLM とは何か|大量の本を読んだ司書が「次の単語」を予測している
「LLM」を一番わかりやすく例えるなら、インターネット上の膨大な本・記事・文章を読み込んで覚えた、巨大な司書です。誰かが質問すると、その司書は頭の中にある膨大な記憶を参照して、「次に出てくる言葉として一番自然なものはこれだろう」と予測して、1 単語ずつ答えを書いていきます。
「Large(大きい)」「Language(言葉)」「Model(仕組み)」の 3 語を分解すると、こうなります。
- Large:とにかく大きい。読み込んだ文章も、覚えている数値の数(パラメータ)も、桁外れに大きいという意味です
- Language:扱う対象は「言葉」。画像や音声を扱うものは別途「画像生成 AI」「音声 AI」と呼ばれます
- Model:仕組み、ひな型、模型のような意味。「言葉のふるまいを真似する仕組み」という感じです
つまり LLM とは 「言葉のふるまいを、とにかく大量に学んだ、巨大な仕組み」 ——これだけです。難しく聞こえる名前ですが、骨組みはシンプルです。
核心は「次の単語を予測している」だけ
LLM がチャット画面で長い文章を返すとき、内部で起きているのは 「次に来る一番自然な単語を、1 つずつ予測して並べているだけ」 です。「今日の天気は」と打つと、LLM は「晴れ」「曇り」「雨」などの候補を比べて確率の高いものを選び、次は「です」を予測し……と単語 1 つずつ繰り返します。
私が営業時代に毎日 60 件ほど訪問していた頃、お客様の話を聞きながら「次にこの方が言いそうな一言は何か」を半歩先で予測する癖が身につきました。LLM がやっているのもこれに近く、膨大な会話のパターンから「次に来そうな一言」を予測する装置——そう捉えると親しみが湧いてきます。
なぜ「大規模」と呼ぶのか
「Large(大きい)」と呼ぶ理由は 2 つの「大きさ」があるからです。1 つ目は 学習データの量で、人間が一生かけても読み切れない分量の文章・書籍・論文・コードを読み込ませています。2 つ目は パラメータの数(言葉と言葉の関係を覚えている数値の数)で、司書の整理棚に何百億・何千億の引き出しがあるイメージです。引き出しが多いほど細かい関係をたくさん覚えていられます。
正確な数字は各バージョンで変わり古くなりやすいので、本記事では「とにかく桁外れに大きい」という肌感だけ持ち帰っていただければ十分です。
LLM の種類と関係|代表 5 系統・ChatGPT・Copilot・RAG の置き場所
📖 この章で使う用語
- GPT / Claude / Gemini:それぞれ OpenAI 社・Anthropic 社・Google 社が作る LLM シリーズ名。ChatGPT・Claude.ai・Gemini アプリの中身。
- OSS(オープンソースソフトウェア):誰でも中身を見て、改変して、再配布できるソフトウェア。LLM では Llama や Mistral が代表例。
- API(注文窓口):プログラムから LLM を呼び出すための窓口。お店のレジで使う注文票のイメージ。
- コード補完:エディタで打ちかけたところに「続きはこうですか?」と AI が提案してくれる機能。Excel のオートコンプリートのプログラミング版。
- RAG(検索拡張生成):LLM が答える前に外部の資料を検索して根拠を持たせる仕組み。
- AIエージェント:LLM に「目的」と「使ってよい道具」を渡し、自律的に手順を考えて動かす仕組み。
この章では、代表的な LLM 5 系統と、ChatGPT・Copilot・RAG といった周辺の言葉が「3 行マップのどこに位置するか」をまとめて整理します。私が業務で API を叩いているのは GPT 系・Claude 系・Gemini 系の 3 系統で、ここは自分の言葉で語ります。Llama 系・Mistral 系は OSS 中心で業務での使い込みはないため、公式の情報をもとに紹介します。
指差せる 5 系統の代表 LLM
| 系統名 | 開発元(会社) | 読者が触れる主な入口 |
|---|---|---|
| GPT 系 | OpenAI 社(米) | ChatGPT / OpenAI API |
| Claude 系 | Anthropic 社(米) | Claude.ai / Anthropic API / AWS Bedrock |
| Gemini 系 | Google 社(米) | Gemini アプリ / Google AI Studio / Vertex AI |
| Llama 系 | Meta 社(米) | Hugging Face / 自社サーバー設置 |
| Mistral 系 | Mistral 社(仏) | Hugging Face / Mistral API |
「Hugging Face(ハギングフェイス)」は OSS の LLM を配布している大型サイトで、OSS 系を試したい開発者がまず来る場所です。
GPT・Claude・Gemini 系(商用 API)— 私が業務で叩いている 3 系統
GPT 系(OpenAI)は「ChatGPT」の中身です。バージョンは GPT-4 やより新しい世代へ更新されますが、「同じ ChatGPT でも中身のモデルは差し替わる」点だけ覚えておいてください(後述)。私は OpenAI の API を自社プロダクトに組み込んでおり、読者が ChatGPT に質問を打つのと同じことを API 越しに自動でやらせています。
Claude 系(Anthropic)は Web では「Claude.ai」、プログラムからは「Anthropic API」、企業向けには「Amazon Bedrock」という入口を通します。私は Anthropic API を日常的に叩き、PoC やコンプライアンス要件で AWS Bedrock 経由で Claude を呼ぶ形も部分的に使っています。Bedrock を選ぶ判断材料や直 API との違い(IAM 連携/VPC 内通信/コスト体系)は概念レベルで語れますが、細かい料金最適化は常用外なので深掘りしません。
Gemini 系(Google)の入口は「Gemini アプリ」「Google AI Studio」「Vertex AI」などです。私は Gemini も API 経由で業務利用し、GPT 系・Claude 系と用途で使い分けています。「どの場面でどの LLM が一番か」は扱うデータ・求める精度・コンプライアンス要件で変わるため、一般化はしません。
初めて触る方には、別記事「ChatGPT 始め方」「Claude 使い方」、料金で迷う方には「Claude 料金プラン」(Free → Pro → Max の段階推奨)をまとめています。
クラウド LLM とローカル LLM の違い——Llama・Mistral 系(OSS)は手元に置ける
Llama(Meta 社)・Mistral(Mistral 社)は OSS として配布される LLM です。ここまでの GPT / Claude / Gemini(クラウド型)との違いは 1 行で言えて、クラウド型はデータが外部サーバーに出る代わりに高性能・手間なし、ローカル型はデータが手元から出ない代わりにマシン性能が要る、というトレードオフです。
| 観点 | クラウド型(GPT / Claude / Gemini) | ローカル型(Llama / Mistral 等) |
|---|---|---|
| データ | 外部サーバーに送る | 手元から出ない |
| 費用 | 月額 or 従量課金 | 無料(電気代・マシン代のみ) |
| 必要なもの | アカウントだけ | メモリの多い PC(Mac 可) |
企業の本番サーバー運用はハードルが高い一方、個人が Apple Silicon の Mac で動かす分には Ollama や LM Studio という無料ツールで現実的に動きます(私も Mac で検証済みの範囲です)。入り口は LLM ローカル入門、ツールの使い方は Ollama 使い方・LM Studio 使い方 に整理しています。なお Llama 系は商用利用にバージョン・規模で変動する条件があるため、使う前に最新の公式ライセンス条項を確認してください。
ChatGPT と LLM の関係|「アプリ名は同じ・中身のエンジンは差し替わる」

サジェスト「llm とは chatgpt」を直球で受けます。ChatGPT は LLM ではなく、GPT 系 LLM を載せたチャットアプリです。 GPT-4 や GPT-5 が「エンジン(LLM 本体)」、ChatGPT が「車体(ユーザー向け製品)」という、全体像の章と同じエンジンと車体の関係です。
表で整理——会社名 / LLM 名 / アプリ名 / API 名
3 大プロバイダの関係を表で整理します。
| 会社 | LLM シリーズ名(エンジン) | チャットアプリ名(一般ユーザー向け) | プログラムから呼ぶ API 名 |
|---|---|---|---|
| OpenAI | GPT シリーズ | ChatGPT | OpenAI API(gpt-4 等のモデル名指定) |
| Anthropic | Claude シリーズ | Claude.ai | Anthropic API(claude-3, claude-4 等) |
| Gemini シリーズ | Gemini アプリ | Google AI Studio / Vertex AI |
混乱しやすいのは、会社名・モデル名・アプリ名が似た名前で並ぶこと。特に Google は「Gemini」が LLM 名でもアプリ名でもあり、ややこしいです。私が API 越しに呼ぶときは claude-sonnet-4-5 のような具体的なモデル名を指定しますが、Claude.ai のチャット画面では「Claude」というアプリ名でしか意識しません。裏ではモデル名、表ではアプリ名——この二重構造を覚えておくと業界用語が一気に理解しやすくなります。
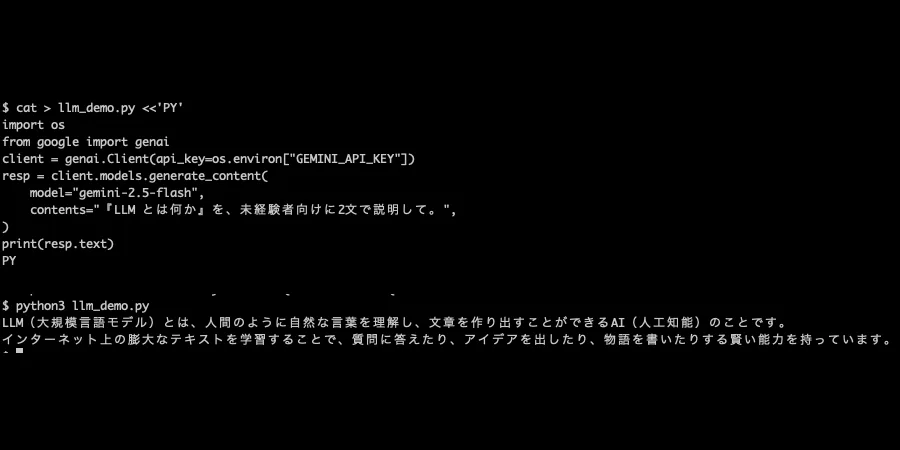
実際に Google の LLM を、アプリ名ではなく モデル名(gemini-2.5-flash) を指定して API から叩いた画面が次です。model="gemini-2.5-flash" と書いて実行すると、Gemini が「LLM とは何か」の説明を返します。私はこの形で GPT・Claude・Gemini を日常的に叩いており、API キーは環境変数経由でコードにも画面にも実値は出していません。
ChatGPT の「中身」が変わるとは?
ニュースの「ChatGPT が更新されました」「GPT-X がリリースされました」は、アプリ名は同じまま中身の LLM がバージョンアップされたという意味です。ある時期は GPT-4 が動き、新世代が出ると差し替わる——アプリ名は変わらず内部エンジンだけ新しくなります。
この構造は API 利用で重要です。プログラム側で gpt-4 と書いても新世代が出た日に自動では切り替わらず、コードを gpt-5 に書き換える必要があります。一方 ChatGPT アプリは提供側が裏で差し替えるため、ユーザーは意識せずバージョンアップを受け取れる、という違いがあります。
GitHub Copilot と LLM の関係|コード補完特化型と「Copilot ≠ 1 製品」
サジェスト「llm とは copilot」を直球で受けます。Copilot は LLM そのものではなく、LLM をコード補完用にチューニングしてエディタに常駐させたプロダクトです。「LLM はエンジン、Copilot はそのエンジンを使う作業空間の 1 つ」と分けて理解すれば混乱しません。
GitHub Copilot — エディタの中の補完アシスタント
GitHub Copilot は、エディタ(Visual Studio Code など)で打ちかけたコードに AI が「続きはこうですか?」と提案するツールです。中身は OpenAI 系の LLM がベースで、最近は Claude や Gemini もユーザーが選べます。
私も業務で使っており、定型ロジック(ループ、ライブラリ呼び出しなど)はほぼ補完任せで書けます。ただし 提案を丸呑みせず自分の頭で 1 回読んで判断する姿勢は崩しません。「動くけど読めないコード」を量産させると後の自分やチームに迷惑がかかるからです。エディタ AI 全般は別記事「Claude Code 使い方」「Cursor 使い方」もどうぞ。
「Copilot」という名前の製品は複数ある
非エンジニア読者が混乱しやすいのが、「Copilot」という名前の製品が複数あることです。すべて Microsoft の「Copilot ブランド」ですが、用途も中身も別物です。
- GitHub Copilot:エディタの中で動くコード補完ツール
- Microsoft 365 Copilot:Excel・Word・PowerPoint・Outlook・Teams の中で動く AI 機能
- Copilot in Windows:Windows OS に組み込まれたチャット型 AI 機能
後者 2 つは私自身は使い込んでおらず、詳しい使い方は各製品の公式ガイドへ。お伝えしたいのは、ニュースで「Copilot」と出てきたら 「どの Copilot の話だろう?」と一度立ち止まると混乱が減る、という点です。
AIエージェント・RAG・チャットボットと LLM の関係|応用の地図
LLM を 土台 とする応用パターンは、いま大きく 3 つ——チャットボット・RAG・AIエージェントです。それぞれ「何を足し算しているか」で区別すると頭に入ります。
| 応用パターン | 構成 | 一言で |
|---|---|---|
| チャットボット | LLM + チャット UI | 最もシンプル。ChatGPT などのチャット画面そのもの |
| RAG | LLM + 外部の資料検索 | 社内ドキュメントや商品カタログを参照させて答えさせる |
| AIエージェント | LLM + 道具を使う能力 | 目的を渡すと、自分で手順を考えて道具を使い分けて動く |
チャットボット — 最もシンプルな LLM 応用
チャットボットは LLM を「人とチャットで会話する」形だけで使うパターンで、ChatGPT・Claude.ai・Gemini アプリも本質的にはこの代表例です。業務で「自社プロダクトにチャット相談窓口を作る」場合も、LLM の API を呼んでチャット欄に答えを出すシンプルな構造で実現でき、私も組み込んだ経験があります。
RAG(検索拡張生成) — LLM + 外部知識
RAG は LLM が答える前に「外部の資料を検索し、見つけた情報を根拠に答える」仕組みです。必要な理由は、LLM 単体は 学習を打ち切った日付までの知識しか持たないから(実力と限界の章で詳述)。社内ドキュメント・商品カタログ・最新ニュースは学習に入らないので、都度検索して結果を LLM に渡してから回答させます。営業時代に商品カタログの該当ページを開いて答えていたのと同じ手順です。
私も業務で RAG を構築し、LangChain・LangGraph(一直線に部品を連結するのが LangChain、状態を持って分岐・ループするのが LangGraph)や、公式 SDK と自前パイプラインの組み合わせで組んできました。ベクトル DB(意味的に近いテキストを素早く取り出す検索データベース)も FAISS・Chroma・Weaviate を使っています。詳しい構造は別記事「RAG とは」へ。
AIエージェント — LLM + ツール実行能力
AIエージェントは LLM に「目的」と「使ってよい道具」を渡すと、自分で手順を考えて道具を使い分けゴールに向かう仕組みです。「来週の出張の航空券を東京→大阪・火曜午前で予約して」と渡すと、「予約サイト検索」「在庫確認」「カート追加」「決済」などの道具を順に使います。RAG が「検索して答える」までなのに対し、エージェントは 「答えるだけでなく行動する」ところまで踏み込みます。
私も組み込んだ経験があり、詳しい構造は別記事「AIエージェントとは」へ。自分で作る側に回るときは「AIエージェント 作り方」で 4 ルート(Python + LangChain / ノーコード / Microsoft Copilot Studio / Claude Projects・GPTs)を実際に使っている範囲で整理しました。
LLM の実力と仕組み|できること・苦手なこと・ハルシネーション・内部構造
📖 この章で使う用語
- ハルシネーション:LLM が「事実でないこと」を、自信満々で本当のように書いてしまう現象。新人時代に「分からないと言えず適当に答えた日」のイメージ。
- モデルカットオフ:LLM が学習を打ち切った日付。それ以降のニュース・新製品などは知らない。
- Transformer:2017 年に登場した、現代の LLM のほとんどが使う内部構造。アテンションで「文中のどの単語に注目するか」を決める。
- トークン:LLM が言葉を数える単位。日本語ではおおむね 1 文字 = 1〜2 トークン。API 料金はこの単位で計算される。「タクシーのメーター」のイメージ。
LLM は万能ではありません。「得意なこと」と「苦手なこと」をはっきり分けておくと、業務での判断がぶれません。
できること 7 つ(実務での頻度順)
私が業務で日常的に LLM にお願いしている作業を、頻度の高い順に書きます。
- 要約:長い議事録・記事・ドキュメントを短くまとめる
- 翻訳:英語の OSS ドキュメントやニュースを日本語に置き換える
- 文章生成:メールの下書き、提案書の骨子、ブログ記事の素案を作る
- コード補完:エディタで打ちかけたコードの続きを提案させる(Copilot などの応用)
- 質問応答(一般知識):「○○ってどういう意味?」程度の質問に答える
- アイデア出し:「この企画のタイトル案を 10 個出して」のような壁打ち
- 構造化:箇条書きの羅列を、表や見出し付きのフォーマットに整える
これらは、いずれも 「文章の中で完結する作業」です。LLM の本質が「次の単語を予測する装置」である以上、文章で表せる作業との相性が抜群です。
できないこと・苦手なこと 5 つ
一方、苦手領域もはっきりしています。知らずに使うと業務で痛い目に遭います。
- 最新の情報:学習データの締切以降のニュース・新製品・新法律などは知りません
- 事実の保証:それっぽい文章は作りますが、書かれている内容が事実かどうかは別問題(ハルシネーション、後述)
- 数値計算の精度:単純な四則演算でも、間違える可能性があります(電卓に任せた方が確実)
- 社内ドキュメントの参照:自社の機密資料は学習に含まれないため、何も知りません(→ RAG が必要)
- 物理世界の操作:ロボット制御や、現実世界のセンサー読み取りはできません(応用の組み合わせで可能になることはありますが、LLM 単体ではできません)
これらは LLM の構造上の限界です。「次の単語を予測する装置」で何でもできると考えると、必ずどこかで裏切られます。
ハルシネーション——LLM 最大の落とし穴
ハルシネーション(hallucination:幻覚)は、LLM が「事実でないこと」を自信満々で本当のように書いてしまう現象です。実在しない論文を「○○年に発表された△△によると……」と引用したり、実在しない人物の言葉を捏造したりする。一見もっともらしいので、知らない人は信じてしまいます。
新人の頃の私が「分かりません」と言えず知ったかぶりで答えて信頼を失った——あれと似たことが LLM にも構造的に起きます。「予測する装置」である以上、もっともらしい予測が事実と一致するとは限りません。
だから基本姿勢は 「LLM の出力を、人間が一度読んで判断する」こと。要約・翻訳・骨子作りなど最終責任を人間が持つ作業なら効率を大幅に上げられますが、正確性が絶対の場面(医療情報・法律相談・財務数値など)でそのまま使うのは避けるべきだと考えています。
LLM の仕組みをざっくり|学習・推論・トークン(興味のある方向け)
ここは 「仕組みまで知りたい方向け」の補足です。読み飛ばして次の業務利用の話に進んでも流れは追えます。「料理人が膨大なレシピを覚え、注文に合わせて即興で皿を組む」というアナロジーで、LLM の流れを 3 段階に分けます。
学習・推論——覚える工程と、答える工程
学習は LLM を作るとき、インターネット上の文章・書籍・コードを何百ギガ〜何テラ読み込ませ、「ある単語の後にどんな単語が来やすいか」を数値で記録する工程です。料理人が修行時代に料理本を読み何万食も作って体に染み込ませるのに近く、巨大な計算機を何ヶ月も走らせる桁外れの仕事になります。
推論(inference)は、学習を終えた LLM が質問を受けて答えを返す工程です。修行を終えた料理人が注文を聞いて即興で皿を組むのと同じで、「次に来る自然な単語」を予測しながら文章を組み立てます。チャット画面のやり取りでは、裏でこの「学習で覚えた関係を使ってリアルタイムに単語を予測する」作業が走っています。
トークン——言葉を数える単位(API 料金に直結)
LLM は言葉を 「トークン」という単位で扱います。目安は英語が「1 単語 = 1〜2 トークン」、日本語が「1 文字 = 1〜2 トークン」(モデルで多少変動)。このトークンが API の 料金単位で、「入力/出力それぞれ 1,000 トークンあたり◯円」という体系です。タクシーのメーターと同じで 長く話すほど料金が積み上がるため、業務ではプロンプトを長くしすぎない・出力上限を設けるなどの設計が大事です(詳細は「Claude 料金プラン」)。
Transformer・アテンションは、興味のある方だけ
現代の LLM のほとんどは 2017 年登場の Transformer という構造を使い、その中核が アテンション(注意機構)——「文中でどの単語が他のどの単語と関係が深いか」を計算する仕組みです。「私は昨日カフェに行った。そこで本を読んだ」の「そこ」が「カフェ」を指すと判断できるのはこの働きです。私は LLM を 「使う側」のエンジニアで内部実装の研究者ではないため、「Transformer で動く」「アテンションが核心」とだけ知っておけば十分とします。深掘りしたい方は各プロバイダの公式ドキュメントや論文「Attention Is All You Need」(2017)から。
業務で LLM を使う|法律の注意点・私の実践・学習の最初の一歩
📖 この章で使う用語
- 利用規約:サービス提供者が定める「使い方のルール」。商用利用可否・データの扱いなどが書かれ、変更頻度が高いので必ず最新版を確認する。
- エンタープライズ経路:AWS Bedrock や Azure OpenAI Service など、企業向けに監査・契約・データ保護を強化した LLM 利用ルート。機密情報を扱う業務で選ばれる。
ここからは業務利用の実務です。まず法律の注意点、次に私が実際に回している使い方と得意技、最後に未経験者向けの学習ステップ——という順で整理します。
サジェスト「llm とは 法律」を受け、最初に大事な前置きを。私は弁護士ではありません。本節は「現役の生成AIエンジニアとして業務で気をつけている観点」のみの共有で、最終的な法律判断は必ず社内の法務・コンプライアンス部門、必要に応じて弁護士にご相談ください。 法律論点は変動が激しく個別事案で判断が分かれるため、「絶対安全」「商用利用可」と断定はできません。
事前に確認している 5 つの観点
業務で LLM を使い始めるとき、私が「最低限ここは事前に確認している」観点を 5 つ挙げます。
- 学習データの著作権:第三者の著作物がどの程度学習に含まれるかは整理が続く状況で、生成物が他者の著作物に似たときのリスクは個別事案で判断が分かれます。使う前に社内法務へ。
- 生成物の商用利用:各サービスの 利用規約に商用利用の可否・条件が書かれていますが、利用規約は頻繁に更新されます。商用利用なら 毎回最新版を確認する運用が安全です。
- 機密情報・個人情報の入力:最も慎重に扱う観点。社外の LLM に入力したデータは「社外に出した」と同等と考えるのが安全側です。「学習に使わない」オプションの効き方・契約上の保証は、情報セキュリティ・法務部門と必ず事前確認を。機密業務では エンタープライズ経路(AWS Bedrock、Azure OpenAI Service、Vertex AI Enterprise など)を検討することが多く、私も一部で AWS Bedrock 経由の Claude を運用しています。ただし使えば自動で安全になるわけではなく、契約・運用設計の確認は必要です(ツール選びは「AI 業務効率化 ツール」も参照)。
- OSS LLM のライセンス:Llama・Mistral などには ライセンス条項があり、Llama 系は商用利用の規模に応じた条件がバージョン・配布形態で変動します。「OSS だから自由」と単純化せず、使うバージョンの最新条項を確認してください。
- AI 規制の動向:EU の AI Act、日本国内のガイドラインなど論点が次々更新される領域です。断定は明日には古くなりうるので、本格利用の前に 最新の一次情報(経産省・総務省・内閣府、EU 公式 AI Act ページなど)を確認してください。
業務で使い始める前に必ずやる 3 つ
5 観点を踏まえ、私が社内で必ずやっているステップです。組織の規模・業界・データの機密度で必要な範囲は変わるので、運用設計は社内の専門部門と一緒に組み立ててください。
- 規約確認:使う予定のサービスの利用規約・データ取り扱いポリシーを最新版で読む
- 社内承認:法務・情報セキュリティ・コンプライアンス部門に計画を共有して承認をもらう
- 運用ルール文書化:「何を入力してよいか/いけないか/生成物のチェック手順」を文書化し全員で共有する
私が実際に回している使い方|コードレビュー 1 次チェックと 4 つの得意技
職種別の架空ユースケースを並べる代わりに、私が実際に業務で LLM をどう回しているかと、その背後にある 4 つの得意技を整理します。私は営業 7 年 → SES → 自社開発という経歴で、いまは生成AIエンジニアとして AI 活用の全社推進を担当しています。
いちばん推進実感のある使い方——コードレビューの 1 次チェック
いちばん効果を実感しているのが、コードレビューの 1 次チェックを LLM に通す使い方です。自分のコードを渡して「考えられる抜け漏れを 10 個指摘して」と頼み、本当に必要なものを取捨選択して直してから人間レビューに回す。レビュアーの負担が下がり、セルフチェック品質も上がる——この両方が全社推進で実際に出ました。
外せないのが 機密コードの取り扱いです。社内コードを外部 LLM に貼ってよいかは社内ルールで事前確認が必要で(前節参照)、エンタープライズ経路を整えている会社ならその経路を使います。
LLM の 4 つの得意技——職種が変わっても効くのはこの 4 つ
コードレビューに限らず、LLM が業務で効く場面は、突き詰めると次の 4 つの得意技に集約されます。職種が違っても効くのはこの組み合わせです。
- 構造化:散らかった情報を型に整える。営業時代の私だったら、商談メモから提案書の骨子(お客様の関心ポイント/提案する 3 つの軸/想定反論への対応)を 5 分で整理するのに毎日使っていたと思います。日報・週報の下書きも同じ要領です。
- 文章生成:定型の文章を素早く作る。「請求書送付の案内」「会議出席依頼」のような定型メールは、件名と相手と要件を渡せば下書きが 30 秒で出ます。固有名詞・社外秘は「○○社さま」のように置換してから渡すのが安全です。
- アイデア出し(壁打ち):1 人で唸る作業の相手になる。記事や提案の構成案を「3 案出して」と頼み、方向性に合うものを選んで肉付けする。LLM は「世間で見かけそうな案」を出しがちなので、丸呑みせず独自の切り口は人間が足すのがコツです。
- 抜け漏れ検出:自分では気づきにくい見落としを列挙させる。10-1 のコードレビューがその代表で、企画書や契約チェックの観点出しにも応用できます。
個人事業主の請求書・業務マニュアルの初稿づくり、副業ライターの構成案出しなども、結局はこの 4 つの組み合わせで説明できます。職種ごとに新しい技を覚えるのではなく、この 4 つを自分の業務に当てはめると捉えると応用が一気に効きます。
共通する姿勢——出力は必ず人間が一度読んで判断する
4 つに共通するのは、「LLM の出力を、人間が一度読んで判断する」姿勢です。得意な作業は高速にやってくれますが、最終責任は人間が持つ——この前提を崩さない限り効果は素直に大きく出ます。逆に丸呑みすると、ハルシネーションや独自性の欠如に足をすくわれます。職種別の話は「AI 業務効率化 事例」「AI 業務効率化 ツール」へ。
学習の最初の一歩|営業出身の私が薦める「触る→使い分ける→広げる」
最後に、これから LLM を学び始める方への提案を 3 ステップで。あくまで 「私の場合は」の話で、生活・職場環境・興味で最適な順番は変わります。
ステップ 1:触る(最初の 1 週間)
ChatGPT または Claude.ai の無料版に登録し、毎日「業務の文章を貼り付ける」だけを続ける。 要約でも英訳でもメールの下書きでもいい、とにかく自分の業務の文章を貼って何が返るかを見る。1 週間で「ここは AI に任せられる/ここは人間の方がいい」という 肌感が体でできてきます。これが本を読むより圧倒的に大事です。始め方は「ChatGPT 始め方」「Claude 使い方」へ。
ステップ 2:使い分ける(次の 1 ヶ月)
慣れてきたら ChatGPT・Claude・Gemini を順番に試し、自分の業務にいちばんハマるものを 1 つ選ぶ。 3 つは少しずつ得意領域が違いますが、「全部使え」では学習が大変なので、まず 1 つに絞って使い込むのがおすすめです。ここで無料版/有料版の判断も来ます。料金の考え方は「Claude 料金プラン」(Free → Pro → Max の段階推奨)へ。ChatGPT・Gemini も基本は似ています。
ステップ 3:広げる(その後、必要に応じて)
メイン 1 つで業務効率化が回り始めたら、応用に広げます。「最低限ステップ 2 まで身につけば当面の業務には十分」というのが私の実感です。
- チームに広げる:自分の業務で効いた使い方を同じ部署に展開する
- 応用パターンを知る:AIエージェント・RAG・チャットボットを学ぶ(「AIエージェントとは」「RAG とは」)
- 他の事例を見る:「AI 業務効率化 事例」「AI 業務効率化 ツール」で他職種・他ツールの組み合わせを知る
最初の壁を、正直に書いておく
未経験から触り始めた多くの方がぶつかる壁は主に 3 つです。「壁にぶつかるのは普通」くらいの心持ちで進む方が長く続きます。
- 登録の心理的抵抗:「カード登録が怖い」「個人情報が不安」。無料版だけならカード不要のサービスもあります(公式で最新情報を確認)
- 英語 UI への抵抗:一部機能は英語のまま。ブラウザの翻訳機能を組み合わせるとハードルが下がります
- 料金プランの不安:特に従量課金の API は複雑に感じます。月額固定(Pro / Max など)から入る方が予算管理しやすいです
「いずれエンジニアにキャリアを広げたい」方は、私の経歴を素材にした「未経験エンジニア転職」もどうぞ。また「クラウドに文章を送りたくない」「小説・創作に使いたい」方は、自分の Mac の中だけで完結する ローカルLLM で小説を書く が次の一歩になります。
よくある質問とまとめ|違い・法律・種類・Copilot・学習の一歩
Q1: LLM と AI、生成AI、ChatGPT の違いを 1 行で教えてください
A. AI は最も大きい言葉、生成AI はその中の「新しく作り出す AI」のカテゴリ、LLM は生成AI の中で「文章を予測する装置」、ChatGPT は LLM を使えるようにしたチャットアプリです。「AI > 生成AI > LLM」の入れ子で、ChatGPT・Claude・Gemini は LLM を載せたアプリの代表例です。
Q2: 業務で LLM を使うのは、法律的に大丈夫ですか?
A. 「絶対大丈夫」とは申し上げません(私は弁護士ではありません)。一般論として注意すべき観点は (1) 利用規約の最新版確認、(2) 機密情報・個人情報を入力しない運用ルール、(3) 生成物の商用利用条件の確認、(4) OSS LLM 使用時のライセンス条項の 4 つです。最終的な法律判断は必ず社内法務部門・コンプライアンス部門、必要に応じて弁護士の方にご相談ください。
Q3: LLM の種類は何種類くらいありますか?
A. 商用サービスとして広く触れる代表は 5 系統(GPT・Claude・Gemini・Llama・Mistral)です。私が業務で API 経由で叩いているのは GPT・Claude・Gemini の 3 系統で、Llama・Mistral 系は OSS 中心のため、公式の情報をもとに整理して触れています。詳細は 代表 5 系統の解説 をご参照ください。
Q4: GitHub Copilot は LLM ですか?それとも違いますか?
A. Copilot は LLM そのものではなく、LLM(OpenAI 系がベース、最近は Claude や Gemini も選べる)をコード補完用にチューニングしてエディタに組み込んだプロダクトです。「LLM はエンジン、Copilot はエンジンを使う作業空間の 1 つ」というイメージで分けて理解すると混乱しません。Microsoft 365 Copilot や Copilot in Windows など、同名の別製品もあるので、ニュースで「Copilot」と出てきたら「どの Copilot か」を一度確認するのがおすすめです。
Q5: LLM を勉強し始めるなら、最初の一歩は何をすればいいですか?
A. 私の場合は「触る → 使い分ける → 広げる」の 3 ステップをお薦めします。まず ChatGPT または Claude.ai の無料版に登録し、1 週間「業務の文章を貼り付ける」だけを続ける。次に ChatGPT・Claude・Gemini を試して自分の業務に合うものを 1 つ決める。最後に AIエージェント・RAG などの応用や、チームへの展開へ広げる——という順序です。詳細は 学習ステップの解説 をご参照ください。
Q6: LLM は自分のパソコン(Mac)でも動かせますか?
A. 動かせます。Llama などの OSS 系 LLM を、Ollama や LM Studio という無料ツールで手元の PC の中だけで動かす方法があり、Apple Silicon の Mac なら個人でも現実的に動きます(私も Mac で検証済みの範囲です)。クラウド型と違いデータが外に出ないのが最大の利点で、文章を外部に送りたくない用途や小説などの創作に向きます。始め方は LLM ローカル入門 に整理しています。
まとめ——LLM を「文章を予測する司書」として味方にする
最後に、本記事の要点を 3 行に圧縮します。
- LLM は道具です。「文章を予測する装置」という核を理解すれば、ChatGPT・Claude・Gemini・Copilot・AIエージェント・RAG までの関係が入れ子の地図として整理できます
- 業務利用は、規約・法律・機密情報の確認とセットです。社内ルールと法的観点を後回しにすると後でつらいので、社内の専門部門と一緒に運用設計するのが安全です
- 学習の最初は「触る」からです。理論書より、毎日 1 週間チャット画面に文章を貼り付ける方が肌感が早く身につきます
LLM は「魔法の杖」ではなく「膨大な本を読んだ司書」のような存在です。何でも知っているわけではなく嘘をつくこともありますが、質問の仕方を工夫すれば思った以上の助けになる。「人間が一度読んで判断する」姿勢を崩さない限り、業務での効果は素直に大きく出ます。本ブログでは関連記事を 20 本近くまとめているので、本記事を起点に興味のある分野へ広げていただけると嬉しいです。
近いうちに、本ブログの内容を体系化した「未経験から生成AIエンジニアになる講座」もご案内予定です。準備が整いましたら、メルマガでお知らせします。
この記事は、法人営業を約 7 年やってから未経験 SE → 自社開発と移ってきた現役の生成AIエンジニア aikun が、OpenAI(GPT)/Anthropic(Claude)/Google(Gemini)の API を業務で日常的に叩いている手触りをもとに書いています。5 系統の代表的 LLM のうち、GPT・Claude・Gemini は業務での実体験をもとに、Llama・Mistral は OSS 中心のため公式の情報をもとに整理しました。LLM の機能・料金体系・利用規約・法的論点は変動が早いため、実際の利用判断は最新の公式情報と利用規約、社内ルール、必要に応じて法務・コンプライアンス部門の判断を優先してください。本記事に対する質問・誤りのご指摘は send@bon-bon-tools.com までお願いします。
出典
- What is a large language model (LLM)? | Cloudflare(取得:2026-05-18)
- What is a large language model (LLM)? | IBM(取得:2026-05-18)
- What is an LLM (large language model)? | AWS(取得:2026-05-18)
- OpenAI API Documentation | OpenAI(取得:2026-05-18)
- Anthropic API Documentation | Anthropic(取得:2026-05-18)
- Gemini API Documentation | Google AI(取得:2026-05-18)
- GitHub Copilot Documentation | GitHub(取得:2026-05-18)
- Llama Models | Meta AI(取得:2026-05-18)
- Mistral AI Documentation | Mistral(取得:2026-05-18)
- Amazon Bedrock | AWS(取得:2026-05-18)
- AI 事業者ガイドライン | 経済産業省・総務省(取得:2026-05-18)
- EU AI Act 公式ページ | European Commission(取得:2026-05-18)
関連記事
- ChatGPT 5.6 とは——Sol/Terra/Luna の違い・選び方・料金を用途で選ぶ一行マップで整理
- LM Studio 使い方——ターミナル不要の GUI でローカル LLM を入れる→モデル管理→OpenAI 互換 API まで、Ollama との使い分けも整理
- Gemini API 使い方——コードから LLM(Gemini)を呼ぶ最小サンプルを Python・GAS で
- 生成AI 入門——5 ペルソナ別 30 日学習プランで通貫整理
- Vertex AI とは——Google Cloud の AI 基盤。Gemini と Claude on Vertex の二本柱・料金・3 基盤比較を業務試用視点で整理
- ローカルLLM 小説の現実——手元で動かす LLM を小説生成に使うときの向くモデル・長文の壁・著作権まで整理
- Azure OpenAI Service とは何か——GPT/Codex モデル一覧・料金・直 API/AWS Bedrock 3 経路使い分け・「Azure に Claude はない」誤解まで整理
- LLM ローカル——Apple Silicon Mac で Ollama を個人検証した経験から、ハードウェア要件・モデル選び・日本語対応まで整理
- Ollama 使い方——入れる→動かす→管理→API組み込みを操作に絞って通しで整理
- AIエージェントとは何か——日常のたとえで丸ごと整理しました
- RAG とは何か——日常のたとえで整理
- FAISS とは——RAG の「検索」を担う Meta 製の無料ベクトル検索ライブラリを業務目線で整理
- LangGraph とは——LLM アプリで状態を持つ複雑なフローを組む道具を業務目線で整理
- LangChain とは——LLM アプリの部品(モデル・検索・記憶・ツール)を連結する土台を、使うとき・使わないときの判断軸で整理
- AI コーディングとは何か——3 つのレイヤーで読み解く実務ガイド
- ChatGPT 始め方——10 分で動かせる最短ルート
- Claude 使い方——3 兄弟整理を丸ごと
- Claude Opus とは何か——4.5 / 4.6 / 4.7 とモデル使い分け整理
- AIエージェント 作り方——4 ルートを業務で実際に使っている範囲で整理しました
- Dify 使い方——ノーコード AI エージェント基盤を業務で扱う現役生成AIエンジニアが、4 アプリタイプ・初心者 5 ステップ・RAG 構築まで整理しました
- Claude Code 使い方——最初の 30 分から解説
- Claude Code 始め方——初回 30 分のステップ
- Cursor 使い方——非エンジニアでも触れる 30 分
- AWS Bedrock とは何か——直 API との料金比較・Claude Code 連携・AgentCore まで整理
- Claude Sonnet 4.6 とは——直 API / Bedrock / GitHub 統合の 3 経路と Opus / Codex 系比較を整理
- Claude Cowork 使い方——もう一人のあなたを動かす
- Claude Opus と Sonnet の違い——3 モデル使い分けと 5 軸比較整理
- Claude 料金プラン——全プランを試した選び方
- AI 業務効率化 事例——5 領域×5 職種で整理しました
- AI 業務効率化 ツール——7 種を目的×職種で整理しました
- AI 議事録 おすすめ——3 系統と用途別使い分けを整理しました
- AI 翻訳 おすすめ——3 ツール用途別整理
- AI 画像生成 無料——UI ベース無料 6 ツール整理
- AI 画像生成 プロンプト——4 要素モデル公開
- AI 動画生成 おすすめ——2 系列と用途別の選び方を整理しました
- エンジニア 転職 未経験——3 段階のキャリアパス整理
- SES やめとけと検索したあなたへ——入口・地雷・出口整理
- AI コードレビューとは何か——プロンプト 5 型・主要 7 ツール・ローカル LLM まで丸ごと整理
- Claude Code Action とは——GitHub Actions に Claude Code を組み込む公式ハーネス
- Claude Skills とは何か——SKILL.md / 自作 3 系統 / Slash commands・MCP・Tools との違いを整理
- AIエージェント × MCP——標準仕様の手と目を増やす設計(自作 MCP サーバー本番運用者が整理)
- Claude Skills を自作する——SKILL.md の書き方から業務 3 系統・チーム配布まで「作る側」を実演
- Vibe coding とは——感覚で AI に書かせ、人間はレビューと方向づけに回る新スタイルを業務実践視点で整理
- Codex CLI とは——OpenAI 系の Claude Code 相当を、両方触った現役の生成AIエンジニアが比較しながら整理しました
- MCP サーバー 作り方——Python/TypeScript SDK で自作し本番運用まで「作る側」の完全マニュアル
- Gemini CLI 使い方——Google のターミナル型 AI コーディングを 3 ツール比較で整理
- Claude Agent SDK とは——Claude Code の中身(自律エージェントの動き)を Python/TS で自分のアプリに組み込む SDK を業務利用視点で整理